
DeepSeek-V4 : pourquoi cette nouvelle version attire autant l’attention ?
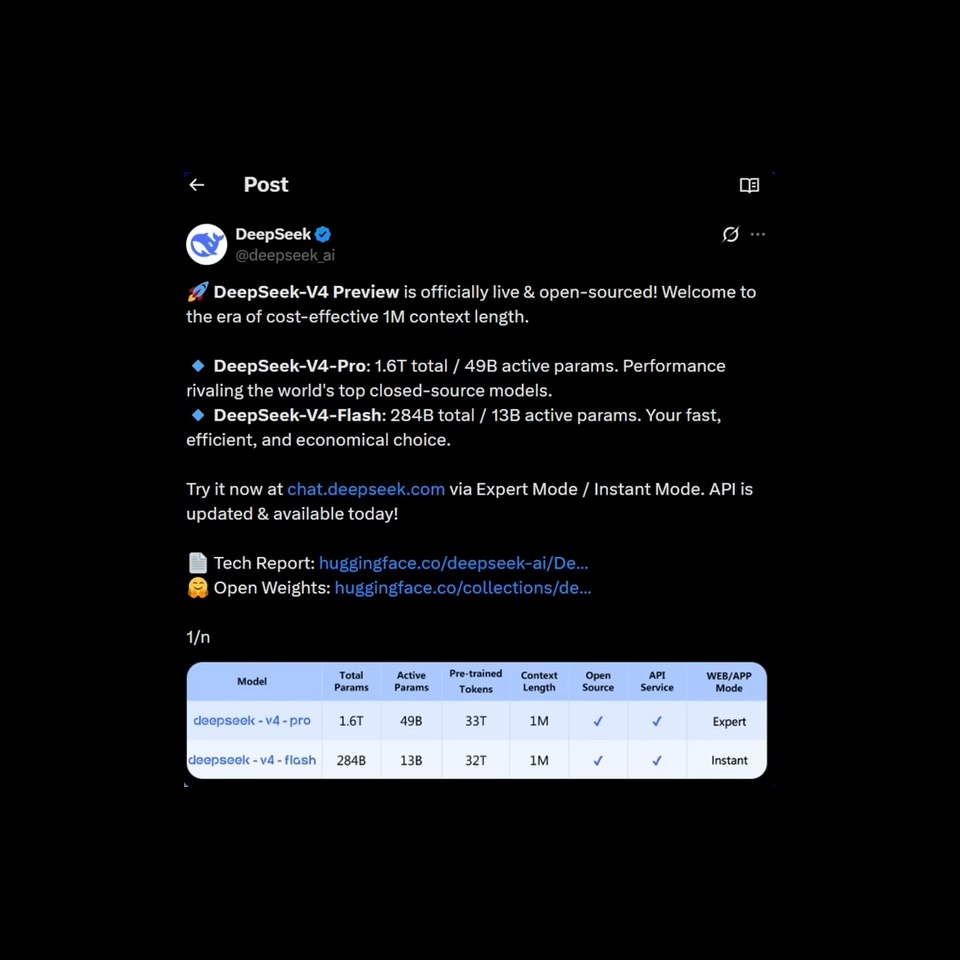
DeepSeek a officiellement lancé DeepSeek-V4 Preview le 24 avril 2026 avec deux variantes : DeepSeek-V4-Pro et DeepSeek-V4-Flash.
Le positionnement est clair : proposer des modèles open weights, capables de rivaliser avec les références fermées du marché, tout en abaissant fortement les coûts d’utilisation.
La promesse la plus marquante ? Un contexte standard de 1 million de tokens.
Autrement dit : analyser un livre entier, une documentation technique massive, une base de code complète ou de longs dossiers juridiques sans découpage complexe devient beaucoup plus accessible.
- V4-Pro : 1,6 trillion de paramètres au total, 49 milliards actifs.
- V4-Flash : 284 milliards de paramètres au total, 13 milliards actifs.
- Les deux modèles : 1M de contexte, API disponible immédiatement, poids ouverts sur Hugging Face.
Ce point est important : le nombre de paramètres “actifs” montre qu’il s’agit d’une architecture MoE (Mixture of Experts). Le modèle complet est immense, mais seule une partie travaille réellement sur chaque requête. Cela permet de gagner en performance sans exploser totalement les coûts.
Le contexte de 1M tokens fait une vraie différence
Beaucoup de professionnels voient encore la fenêtre de contexte comme un détail technique. En réalité, c’est souvent ce qui limite le plus les usages avancés.
Quand un modèle oublie le début d’un document ou nécessite un découpage manuel, la productivité chute vite.
Avec 1 million de tokens, DeepSeek veut faire du long contexte non plus une option premium, mais un standard.
Pour un développeur, cela signifie :
- charger un projet complet.
- garder l’historique d’un raisonnement complexe.
- éviter les pertes d’informations entre plusieurs échanges.
Pour une équipe marketing ou e-commerce, cela peut vouloir dire analyser des rapports entiers, des verbatims clients massifs ou plusieurs mois de performances sans fragmentation artificielle.
V4-Pro ou V4-Flash : lequel vise quel usage
Les deux modèles ne répondent pas au même besoin.
| Modèle | Positionnement | Usage principal |
|---|---|---|
| DeepSeek-V4-Pro | Performance maximale | Agentic coding, raisonnement complexe, math, STEM, tâches expertes. |
| DeepSeek-V4-Flash | Vitesse + coût réduit | Chat rapide, automatisation à grande échelle, tâches simples à intermédiaires. |
V4-Pro est celui qui concentre l’attention médiatique. DeepSeek affirme qu’il rivalise avec les meilleurs modèles fermés sur plusieurs benchmarks de code, de raisonnement et de connaissances.
V4-Flash, lui, est probablement plus stratégique pour beaucoup d’entreprises : moins cher, plus rapide, et suffisant pour une grande partie des usages quotidiens.

Tout le monde n’a pas besoin du modèle le plus puissant. Beaucoup ont surtout besoin d’un bon rapport performance/prix.
Le vrai sujet : les prix API
C’est ici que DeepSeek frappe fort.
Le discours n’est pas seulement “nous sommes puissants”, mais surtout : nous sommes beaucoup moins chers.
Pour les entreprises qui utilisent massivement des API, cela change rapidement les arbitrages budgétaires.
Quand les volumes explosent, quelques centimes par million de tokens deviennent un vrai sujet stratégique.
L’innovation technique derrière DeepSeek-V4
Le point le plus intéressant n’est pas seulement la taille du modèle, mais la manière dont DeepSeek rend ce contexte long exploitable.
Le rapport technique met en avant une nouvelle approche d’attention sparse appelée DSA (DeepSeek Sparse Attention), combinée à une compression token par token.
L’objectif : réduire drastiquement les besoins en mémoire et en calcul.
- 27 % des FLOPs de V3.2 à 1M de contexte.
- 10 % du KV cache mémoire.
Dit plus simplement : ils essaient de rendre le très long contexte économiquement viable, et c’est probablement là que se joue la vraie bataille.
Un autre signal fort : l’optimisation pour les puces Huawei
Autre élément très commenté : DeepSeek-V4 est adapté aux puces Huawei Ascend, et non uniquement à l’écosystème NVIDIA.
Cela montre une volonté claire d’indépendance technologique et une stratégie industrielle plus large côté chinois.
Reuters souligne d’ailleurs que cette adaptation est perçue comme une étape importante vers davantage d’autonomie dans l’écosystème IA chinois.
Faut-il croire toutes les promesses de DeepSeek-V4 ?
Non. Et c’est important de garder du recul.
Comme toujours avec ce type de lancement, il faut distinguer :
- les benchmarks internes.
- les performances réelles en production.
- les usages quotidiens des équipes.
Un excellent score en benchmark ne garantit pas automatiquement une meilleure expérience sur des workflows métier réels.
Autre limite importante : malgré les performances annoncées, DeepSeek reconnaît lui-même rester derrière certains leaders sur les connaissances générales et certains usages très complexes.
Il faut aussi rappeler que “open weights” ne veut pas dire “facile à héberger localement”. Un modèle de cette taille reste extrêmement lourd à déployer et quasi inexploitable pour le professionnel du digital moyen qui ne dispose pas d’un serveur très puissant à disposition.
Pour beaucoup d’entreprises, son éventuelle utilisation passera donc d’abord par l’API, et non par le self-hosting.

Principalement passionné par les nouvelles technologies, l’IA, la cybersécurité, je suis un professionnel de nature discrète qui n’aime pas trop les réseaux sociaux (je n’ai pas de comptes publics). Rédacteur indépendant pour LEPTIDIGITAL, j’interviens en priorité sur des sujets d’actualité mais aussi sur des articles de fond. Pour me contacter : [email protected]


