
Accès rapide (Sommaire) :
Gemini Omni Flash : la nouvel super-IA vidéo de Google
Depuis l’explosion des modèles génératifs comme Sora, Runway, Pika ou encore Kling AI, le secteur de la vidéo générée par IA progresse rapidement… mais avec une limite importante : la difficulté à conserver la cohérence d’une scène au fil des modifications.
C’est précisément là que Gemini Omni Flash tente de se différencier.
Google ne présente pas seulement un outil de création vidéo, mais un modèle multimodal capable de “raisonner” sur les contenus qu’il manipule.
En clair : l’IA ne se contente plus de produire une séquence visuellement attirantes, elle essaie aussi de comprendre les relations physiques, narratives et contextuelles entre les éléments.
La promesse est ambitieuse : transformer n’importe quelle combinaison d’images, de texte, d’audio ou de vidéo en une nouvelle vidéo cohérente, modifiable par conversation naturelle.
Google parle d’ailleurs explicitement d’un modèle “create anything from any input”. Cette formulation rapproche Gemini Omni d’un système de création universel plutôt que d’un simple générateur vidéo.
Pourquoi certains parlent déjà du “Nano Banana de la vidéo” ?
Le parallèle avec Nano Banana n’est pas anodin. Le modèle de Google dédié à l’image avait surpris par sa capacité à modifier des visuels avec une grande continuité stylistique et contextuelle.
Gemini Omni applique désormais cette logique à la vidéo :
- les personnages restent cohérents ;
- les décors conservent leur continuité ;
- les objets persistent d’une scène à l’autre ;
- les modifications successives ne “cassent” plus totalement la vidéo.
C’est un changement majeur. Jusqu’ici, la plupart des générateurs vidéo produisaient surtout des clips courts difficilement éditables. Chaque nouvelle génération impliquait souvent de repartir quasiment de zéro.
Avec Gemini Omni Flash, Google tente de transformer la vidéo IA en environnement itératif, proche d’un logiciel de montage conversationnel.
L’édition conversationnelle : le vrai pari de Google sur la vidéo IA
Dans les démonstrations de Google, ce qui retient le plus l’attention n’est pas tant la qualité visuelle des vidéos produites, d’autres solutions génèrent déjà des rendus très convaincants.
Ce qui marque vraiment, c’est la capacité à éditer une vidéo par simple conversation.
Concrètement, l’utilisateur peut modifier un élément précis, ajuster l’ambiance, intégrer des effets, transformer une action, changer le décor ou réécrire une scène étape par étape.
Et surtout : chaque retouche tient compte de ce qui a été demandé avant.
C’est là que Gemini Omni se rapproche des usages professionnels réels. Dans un workflow créatif classique, une vidéo se valide rarement du premier coup.
Les allers-retours font partie du processus. Google cherche précisément à reproduire cette logique : non plus générer, puis recommencer depuis zéro, mais affiner de manière continue.
Pour les créateurs de contenu, les agences ou les équipes social media, l’enjeu devient concret :
| Avant | Avec Gemini Omni |
|---|---|
| Régénérer plusieurs clips | Modifier la vidéo existante |
| Perte fréquente de cohérence | Contexte conservé tout au long |
| Workflow fragmenté | Édition conversationnelle continue |
| Multiples outils nécessaires | Approche unifiée et multimodale |
Google veut injecter la “compréhension du monde réel” dans la vidéo IA
L’autre axe central de Gemini Omni Flash concerne la physique et la logique des scènes générées.
C’est un point souvent sous-estimé dans les vidéos IA actuelles. Beaucoup de modèles savent créer des images magnifiques… mais incohérentes dès qu’un mouvement complexe intervient.
Objets qui traversent les surfaces, gravité incohérente, mouvements impossibles, interactions physiques absurdes : ces défauts restent fréquents.
Google affirme avoir fortement amélioré cet aspect grâce au raisonnement multimodal de Gemini.
Dans les exemples montrés :
- des réactions en chaîne respectent mieux l’inertie ;
- les fluides semblent plus naturels ;
- les interactions entre objets paraissent plus crédibles ;
- les scènes complexes gardent une continuité temporelle plus stable.
Ce n’est pas seulement esthétique. Pour les usages professionnels (publicité, formation, cinéma, visualisation produit) la crédibilité physique devient essentielle.
Google tente ici de dépasser le stade du “clip impressionnant pour réseaux sociaux” afin d’aller vers des contenus exploitables dans des environnements plus exigeants.
La multimodalité devient enfin concrète dans un produit grand public
Le terme multimodal est utilisé partout dans l’IA depuis deux ans, souvent de manière très théorique.
Avec Gemini Omni, Google commence à montrer un usage réellement tangible de cette approche.
Le système peut utiliser simultanément :
- une image comme référence esthétique ;
- une vidéo pour le mouvement ;
- un fichier audio pour le rythme ;
- un prompt textuel pour la direction artistique.
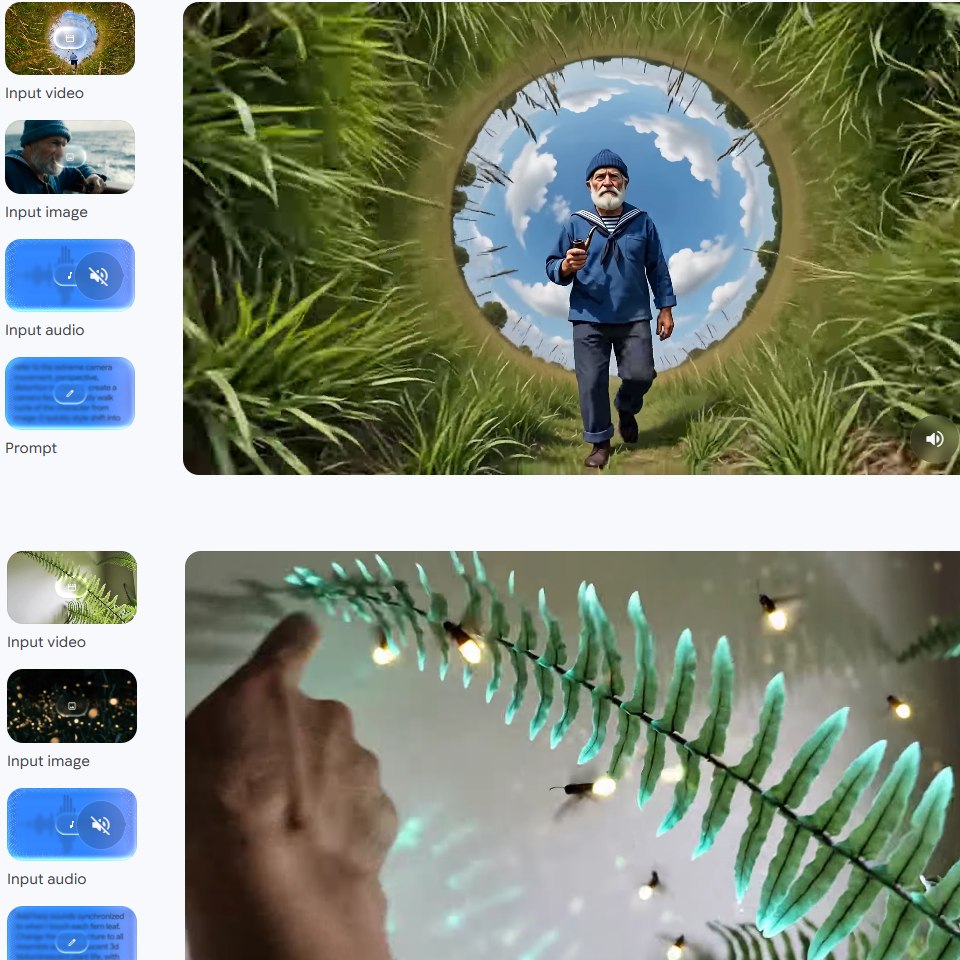
Cette fusion des médias pourrait profondément modifier la création de contenus marketing et publicitaires.
Jusqu’ici, produire une vidéo cohérente impliquait souvent :
- un outil de montage ;
- un générateur audio ;
- des logiciels d’animation ;
- des plateformes d’effets spéciaux ;
- des banques de médias.
Google pousse ici une vision beaucoup plus intégrée où l’IA devient une couche de création universelle.
Pour les créateurs indépendants et les PME, cette évolution pourrait considérablement réduire les coûts de production vidéo.
Les avatars IA montrent que Google avance prudemment sur les deepfakes
Google sait que la génération vidéo IA soulève immédiatement des questions sensibles autour de la désinformation et des deepfakes.
L’entreprise adopte donc une approche relativement prudente sur les avatars numériques.
Pour le moment, les utilisateurs peuvent uniquement créer un avatar basé sur leur propre voix et leur propre apparence.
Google précise aussi que les fonctionnalités de modification avancée de voix et de parole ne sont pas encore totalement ouvertes, justement pour des raisons de sécurité.
Ce point est important car la frontière entre outil créatif, assistant vidéo et générateur de faux contenus réalistes devient de plus en plus mince.
Google tente donc d’anticiper les critiques en mettant en avant :
- SynthID, son watermark invisible ;
- des outils de vérification intégrés ;
- la transparence sur les contenus générés.
Reste néanmoins une grande inconnue : ces mécanismes seront-ils réellement efficaces lorsque les vidéos générées commenceront à circuler massivement hors de l’écosystème Google ?
Quid de la disponibilité ? Gemini Omni Flash est déjà disponible… mais pas encore pour tout le monde
Google déploie progressivement Gemini Omni Flash dans plusieurs produits :
- l’application Gemini ;
- Google Flow ;
- YouTube Shorts ;
- YouTube Create.
Cependant toutes les fonctionnalités montrées durant Google I/O 2026 ne sont pas encore disponibles à grande échelle.
À court terme :
- les abonnés Google AI Plus, Pro et Ultra sont prioritaires ;
- certaines capacités multimodales audio restent limitées ;
- les APIs développeurs arriveront plus tard ;
- les usages professionnels restent encore en phase d’ouverture progressive.
Autrement dit, Google présente déjà la vision finale… mais le produit réel reste partiellement en construction.
C’est un schéma désormais classique dans l’industrie de l’IA générative : les démonstrations donnent souvent un aperçu des capacités maximales du modèle, pas nécessairement de l’expérience utilisateur immédiatement accessible.

Rédactrice web pour LEPTIDIGITAL, je vous aide à décrypter l’actualité du numérique simplement. Pour me contacter : [email protected]


