
Accès rapide (Sommaire) :
GPT-Realtime-2 : quand la voix devient une interface opérationnelle
Depuis plusieurs années, les assistants vocaux promettent des interactions plus naturelles avec les logiciels.
Pourtant, dans les faits, la plupart de ces systèmes restent limités :
- compréhension approximative ;
- latence trop élevée ;
- mauvaise gestion du contexte ;
- incapacité à gérer des interruptions ;
- difficultés avec les accents ou les langues mixtes.
Le vrai problème n’était donc pas la synthèse vocale, c’était la capacité du système à raisonner pendant qu’il écoute.
Avec GPT-Realtime-2, OpenAI cherche clairement à franchir cette étape. L’objectif n’est plus simplement de répondre oralement à une question.
Le modèle doit désormais :
- comprendre une demande complexe ;
- maintenir un contexte conversationnel long ;
- utiliser des outils en parallèle ;
- corriger ses erreurs ;
- adapter son ton ;
- continuer à converser pendant qu’il traite une action.
Autrement dit : la voix devient une couche d’orchestration opérationnelle.
Ce changement est important, car il rapproche les interactions vocales du fonctionnement humain réel.
Une personne ne parle pas en attendant silencieusement qu’un système réfléchisse pendant plusieurs secondes.
Elle veut une conversation fluide, contextualisée et dynamique.
Fini le silence gêné : GPT-Realtime-2 ne perd plus le fil
Le cœur de cette annonce est clairement GPT-Realtime-2. OpenAI le présente comme son premier modèle vocal doté d’un niveau de raisonnement comparable à celui de GPT-5.
Le système ne se contente plus de transformer de la parole en texte avant de générer une réponse.
Il est capable de :
- analyser une demande complexe en temps réel ;
- gérer plusieurs étapes logiques ;
- faire appel à plusieurs outils simultanément ;
- adapter sa réponse selon le contexte émotionnel ;
- continuer la discussion même en cas d’interruption.
La fin des conversations robotiques
Jusqu’ici, beaucoup d’agents vocaux fonctionnaient comme des arbres décisionnels améliorés. Dès qu’une conversation devenait ambiguë ou sortait du scénario prévu, les limites apparaissaient rapidement.
Avec cette nouvelle génération, le système peut :
- poser des questions de clarification ;
- revenir sur une erreur précédente ;
- modifier son raisonnement ;
- garder un historique de discussion beaucoup plus long.
OpenAI annonce d’ailleurs un passage de 32K à 128K de contexte. Cette évolution est loin d’être anodine. Dans un centre d’appel par exemple, un support technique ou un assistant métier, cela permet de conserver l’historique complet d’une conversation complexe sans perdre le fil.
Des réponses plus humaines… mais surtout plus transparentes
Un point particulièrement intéressant concerne les “preambles”.
Le système peut désormais dire :
- “Je vérifie votre agenda” ;
- “Laissez-moi regarder cela” ;
- “Je rencontre un problème actuellement”.
Cela peut sembler anecdotique, pourtant, c’est essentiel dans une interaction vocale.
Le silence crée de l’incompréhension, une voix qui verbalise ses actions donne une impression de continuité et réduit la frustration utilisateur.
GPT-Realtime-Translate : la traduction instantanée devient enfin crédible
Le second modèle présenté est probablement celui qui pourrait avoir l’impact commercial le plus immédiat.
GPT-Realtime-Translate permet de traduire des conversations vocales en temps réel : plus de 70 langues en entrée, 13 langues de sortie, avec transcription en direct.
La différence ici ne réside pas seulement dans la traduction, le vrai défi est la gestion du rythme conversationnel.
Les systèmes de traduction vocale souffrent souvent :
- de latence ;
- de pertes de contexte ;
- d’erreurs sur les accents ;
- de difficultés avec le vocabulaire métier ;
- de confusion lorsqu’une personne mélange plusieurs langues.
OpenAI affirme avoir fortement amélioré ces aspects, notamment sur les langues régionales et les contextes multilingues complexes.
Le multilingue en temps réel sous conditions
Plusieurs secteurs pourraient être rapidement transformés :
- support client international ;
- tourisme ;
- santé ;
- formation ;
- événementiel ;
- service après-vente.
Un support multilingue coûtait historiquement très cher. Avec des modèles capables de traduire et contextualiser en temps réel, les barrières opérationnelles diminuent fortement.
Cela dit, plusieurs inconnues demeurent :
- gestion du bruit ambiant ;
- accents très marqués ;
- vocabulaire technique rare ;
- fiabilité juridique ;
- confidentialité des échanges.
GPT-Realtime-Whisper : la transcription temps réel entre dans une nouvelle phase
OpenAI relance également sa technologie de transcription avec GPT-Realtime-Whisper. L’objectif est de produire des transcriptions vocales quasi instantanées avec une latence minimale.
Ce type de système peut sembler moins spectaculaire que le raisonnement vocal. Pourtant, c’est souvent la brique la plus importante.
Pourquoi ? Parce qu’une mauvaise transcription détruit toute la chaîne de compréhension.
Les usages potentiels sont immenses :
- réunions automatiques ;
- sous-titrage en direct ;
- prise de notes ;
- support client ;
- centre d’appels ;
- recrutement ;
- médias ;
- cours et conférences.
Le point intéressant est l’intégration directe dans le flux conversationnel. La transcription n’est plus un traitement “après coup”. Elle devient un composant temps réel exploitable immédiatement.
Les trois modèles fonctionnent ensemble : c’est probablement le vrai tournant
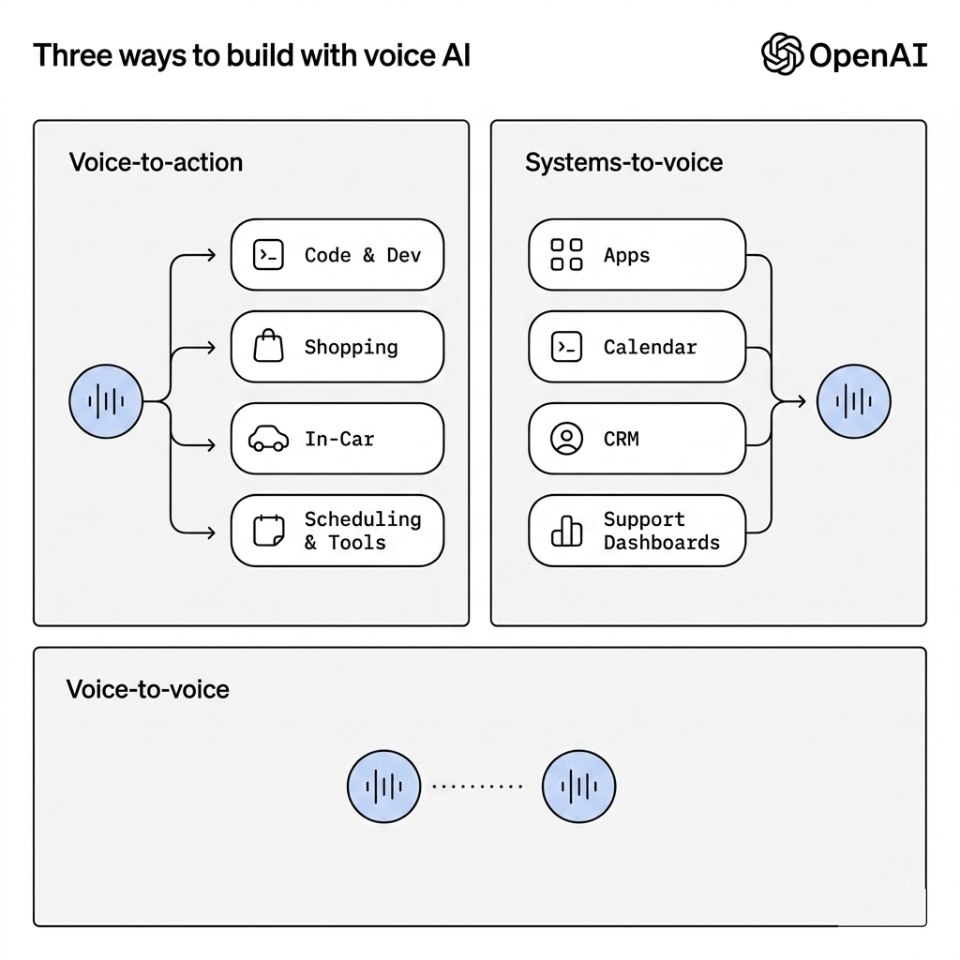
Pris séparément, chaque modèle est intéressant.
Mais la vraie rupture vient surtout de leur combinaison :
- écouter ;
- transcrire ;
- raisonner ;
- traduire ;
- agir.
Tout cela dans un même flux conversationnel.
On observe ici une évolution importante : la voix devient un système d’orchestration métier, et plus uniquement une interface utilisateur.
Tarifs, disponibilité et accès : qui peut utiliser ces modèles aujourd’hui ?
Les trois modèles sont disponibles via la Realtime API d’OpenAI.
Voici les prix annoncés :
| Modèle | Tarification annoncée |
|---|---|
| GPT-Realtime-2 | 32 $ / 1M tokens audio entrants et 64 $ / 1M tokens audio sortants. |
| GPT-Realtime-Translate | 0,034 $ par minute. |
| GPT-Realtime-Whisper | 0,017 $ par minute. |
OpenAI met également à disposition :
- un Playground de test ;
- une intégration via Codex ;
- des outils de sécurité dans l’Agents SDK ;
- la résidence des données pour l’Union européenne.

Rédactrice web pour LEPTIDIGITAL, je vous aide à décrypter l’actualité du numérique simplement. Pour me contacter : [email protected]


