Vous souhaitez utiliser un modèle d’intelligence artificielle (LLM) directement sur votre Mac sans dépendre d’une application externe ? Ollama est une solution idéale qui vous permet de travailler localement, tout en gardant un contrôle total sur vos données. Découvrez comment installer Ollama et l’utiliser sur MacOS.
Pourquoi installer un modèle d’intelligence artificielle local sur MacOS ?
Les modèles d’intelligence artificielle comme ceux proposés par OpenAI ou Google sont souvent accessibles via Cloud. Leur utilisation via ce système peut poser des questions importantes sur la confidentialité des données.
Vous ne le savez peut-être pas, mais, lorsque vous utilisez une IA basée sur le cloud, vos données et requêtes peuvent être transmises à des serveurs tiers, où elles sont potentiellement stockées ou utilisées à d’autres fins (notamment pour entraîner les modèles – vous pouvez lire notre article sur limiter l’utilisation des données sur ChatGPT).
Avec un LLM local, vous installez et exécutez l’intelligence artificielle directement depuis votre ordinateur. Par conséquent, aucune donnée ne sera divulguée en dehors de votre appareil.
Parmi les modèles existants sur macOS, Ollama se distingue par sa protection des données, sa facilité d’installation et son accessibilité au grand public. Nous allons vous expliquer comment l’installer.
Installer Ollama sur un Mac
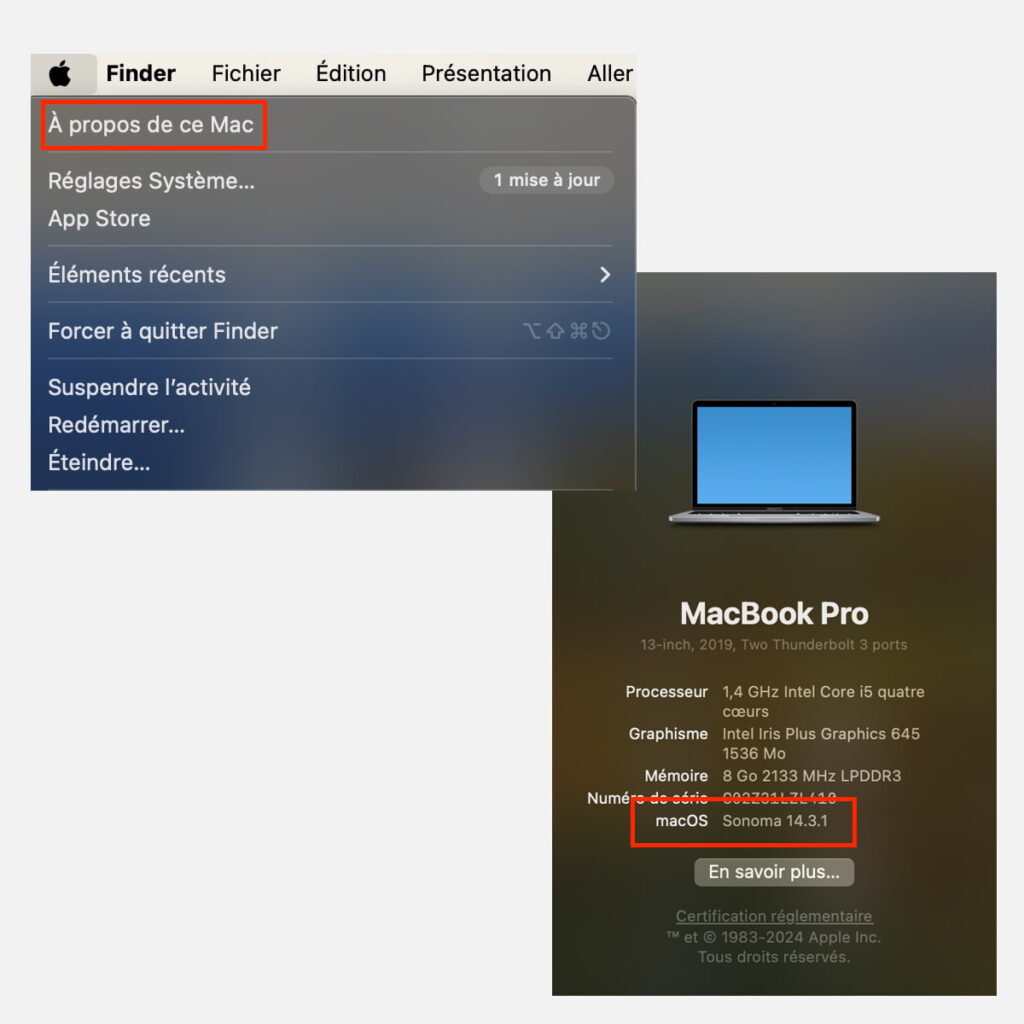
Avant de commencer l’installation, il faut vérifier que vous disposez d’un espace de stockage suffisant (minimum 2Go) pour télécharger les modèles de langage (Ollama ne prend pas beaucoup de place) et que votre Mac est compatible avec macOS 11 ou une version plus récente du système d’exploitation (icône Pomme en haut à gauche de votre écran > À propos de ce Mac).
Comment Vérifier sa Version MacOS ?
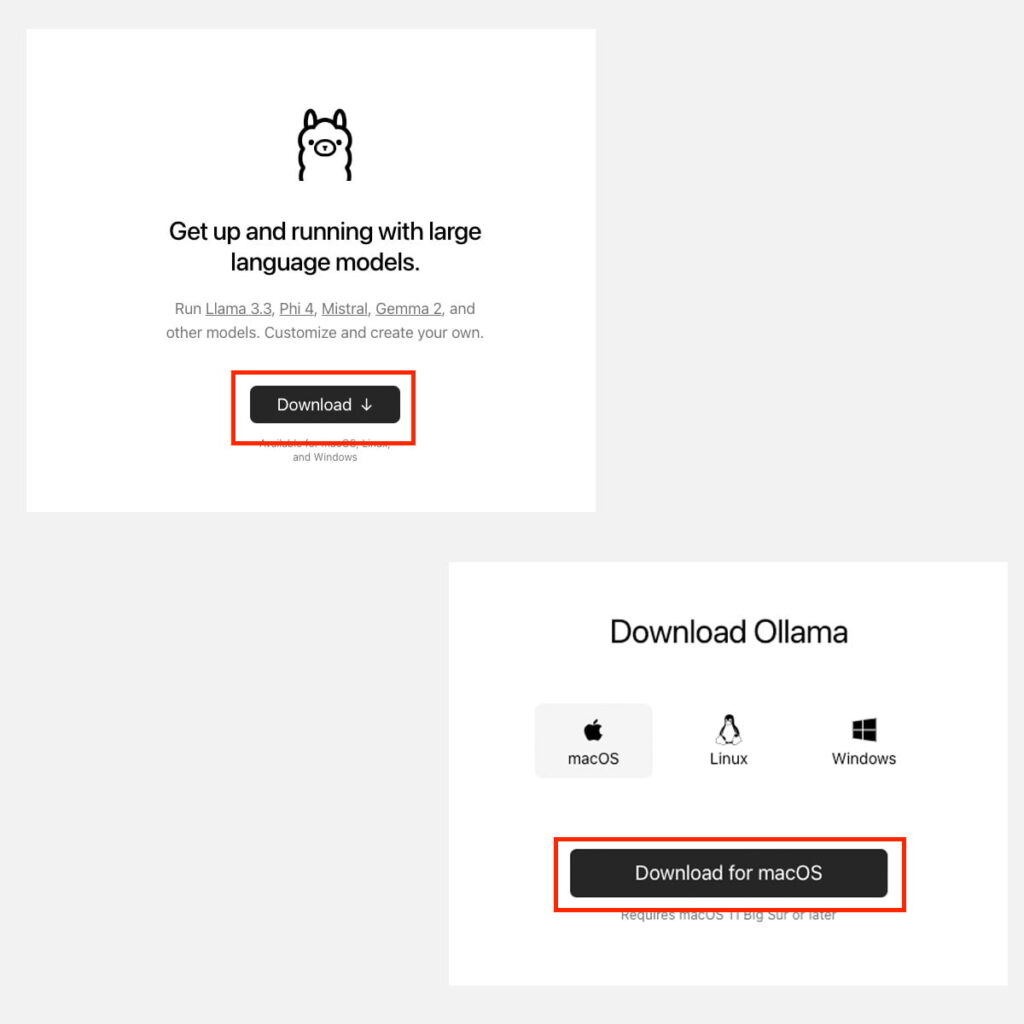
1. Téléchargez le fichier d’installation sur le site Ollama. Cliquez sur Download, puis Download MacOS ;
Télécharger Fichier Installation Ollama
2. Une fois le fichier d’installation téléchargé, dézippez le fichier et double-cliquez dessus pour l’installer sur votre Mac ;
3. Dès l’ouverture de l’application, cliquez sur Next. Lorsque vous y êtes invité, entrez votre mot de passe administrateur Mac. Cela permet de donner à Ollama les permissions nécessaires pour s’installer correctement ;
4. Puis cliquez sur Install et sur Finish ;
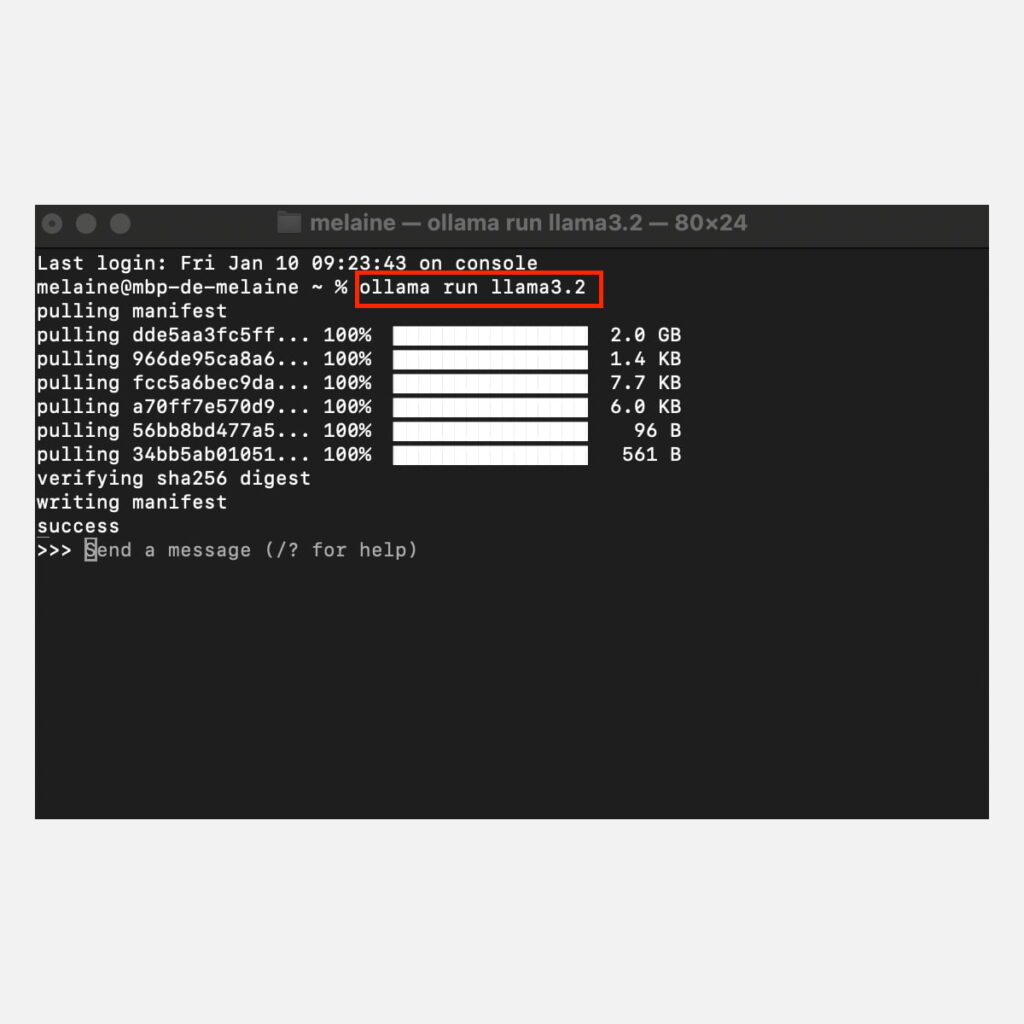
5. Ensuite, rendez-vous dans le Terminal de votre Mac et exécutez la commande « ollama run llama3.2 » pour télécharger le modèle Llama 3.2. (Si vous avez besoin d’un autre modèle, vous pouvez consulter la bibliothèque de modèles Ollama en ligne. Remplacez simplement llama3.2 par le nom du modèle que vous souhaitez, comme llama3.3.)
Aperçu de l’Installation de Llama 3.2
6. Patientez jusqu’à l’installation complète du logiciel. À la fin de l’installation, vous verrez ce message apparaître « >>> Send a message (/ ? for help)«
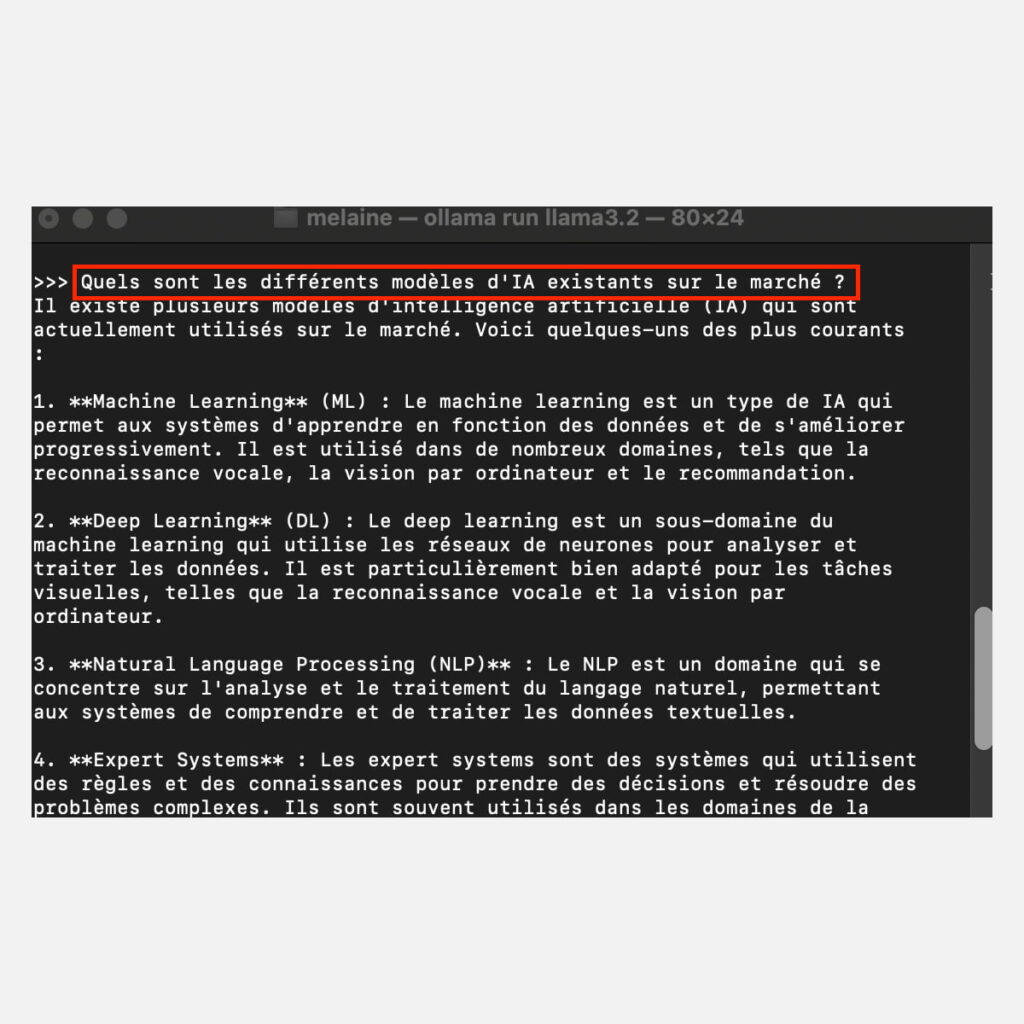
7. Une fois le modèle téléchargé et prêt à l’emploi, vous pouvez interagir avec l’IA directement depuis le terminal. Par exemple, demandez-lui « Quels sont les différents modèles d’IA existants sur le marché ?«
Aperçu d’une Requête et Réponse Générée par Llama 3.2 sur MacOS
Si vous avez besoin d’aide, n’hésitez pas à utiliser « /? » pour accéder à la liste des commandes et des instructions.
8. Pour quitter Ollama, vous pouvez fermer l’application en entrant la commande /bye.
9. Pour lancer une nouvelle session, vous avez seulement à taper « ollama run llama3.2 » dans le terminal.
Quelques conseils pour optimiser l’utilisation des modèles IA sur votre Mac
Supprimer les modèles que vous n’utilisez pas : pour supprimer Llama 3.2 il suffit de taper dans le terminal « ollama rm llama3.2 » ;
Privilégier les modèles qui ne prennent pas trop de place sur votre espace disque ;
Quand vous lancez un modèle depuis votre terminal, fermez les applications dont vous n’avez pas besoin pour réduire la charge sur le processeur ;
Exportez vos conversations en copiant-collant dans un document Word par exemple et créez un dossier pour répertorier tous vos échanges avec le modèle.
Anciennement E-Store Manager et Social Media Manager en agence et chez l’annonceur, je m’intéresse principalement aux sujets liés au Community Management, au Social Media Advertising et au E-commerce au sens large. Je suis aussi toujours à l’affût des dernières tendances webmarketing et couvre ces sujets pour LEPTIDIGITAL. Pour me contacter : [email protected]