Accès rapide (Sommaire) :
66 milliards de requêtes analysées : ce que cette étude mesure réellement
Avant d’interpréter les chiffres, il faut comprendre précisément ce qui a été analysé.
L’étude de HOSTINGER repose sur l’analyse de 66,7 milliards de requêtes automatisées issues des journaux serveurs de plus de 5 millions de sites web, réparties sur trois périodes distinctes de l’année.
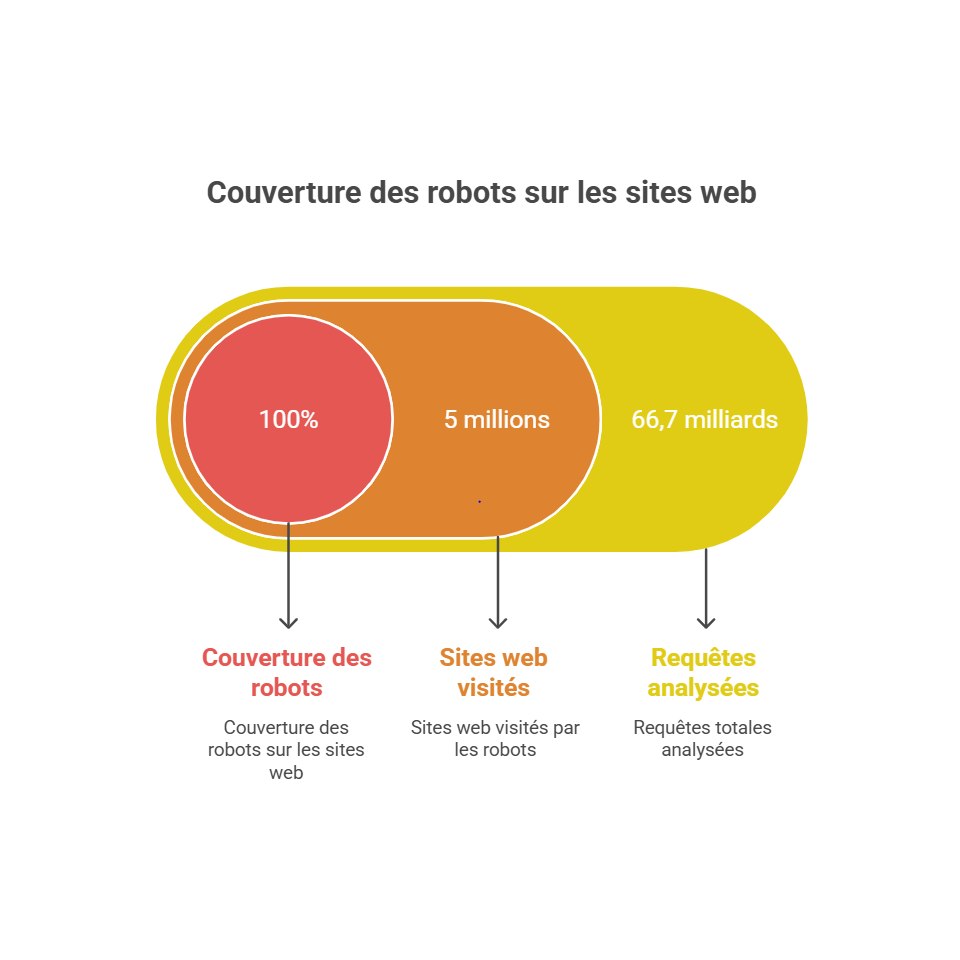
Chaque requête a été attribuée à un robot identifié grâce à son user-agent, puis classée par fonction réelle : exploration de moteurs de recherche, collecte de données, analyse SEO, assistants conversationnels, réseaux sociaux, etc.
Les robots du web en 2026 : chacun son rôle, chacun son accès
Historiquement, le web était principalement exploré par les robots des moteurs de recherche classiques.
Aujourd’hui, ce paysage s’est fragmenté. Les robots poursuivent des objectifs très différents, et les sites commencent à les traiter de façon sélective.
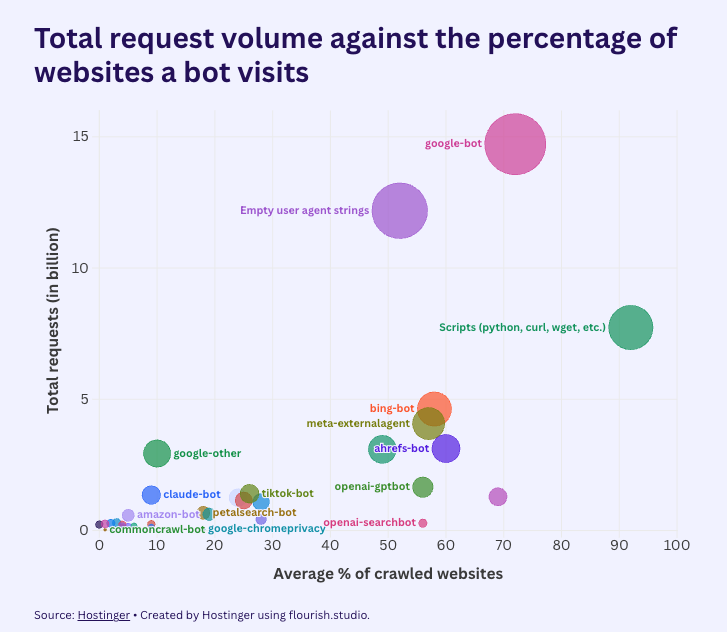
Voici les 3 principaux types de robots observés :
1- Les robots des moteurs de recherche classiques
Google et Bing continuent de parcourir une large partie du web, avec une stabilité remarquable. Googlebot atteint environ 72 % de couverture, Bingbot autour de 58 %.
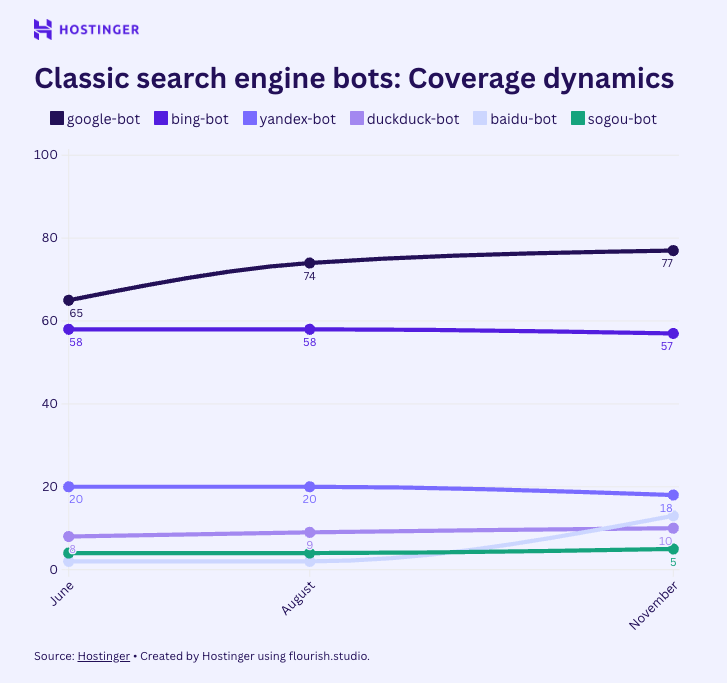
Leur rôle reste inchangé : indexer les pages pour les afficher dans les résultats de recherche.
Bloquer ces robots revient toujours à disparaître des moteurs et des résultats de recherche organiques.
2- Les robots de collecte pour l’entraînement des modèles
Ces robots collectent massivement du contenu pour constituer ou enrichir des bases de données.
Contrairement aux moteurs de recherche, ils ne renvoient pas directement de trafic.
Le signal est clair : leur accès chute brutalement.
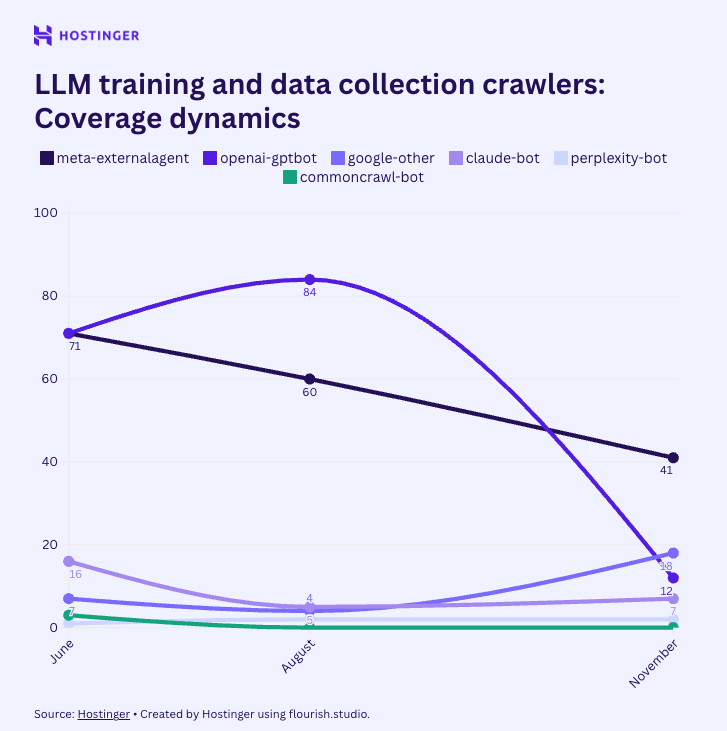
Certains, comme GPTBot, passent d’une présence quasi généralisée à une couverture marginale.
Les éditeurs ferment également de plus en plus la porte à ce type de crawlers.
3- Les robots orientés assistants et recherche conversationnelle
C’est ici que le changement est le plus marquant.
Les robots qui alimentent des assistants capables de répondre à des questions précises voient leur accès augmenter rapidement.
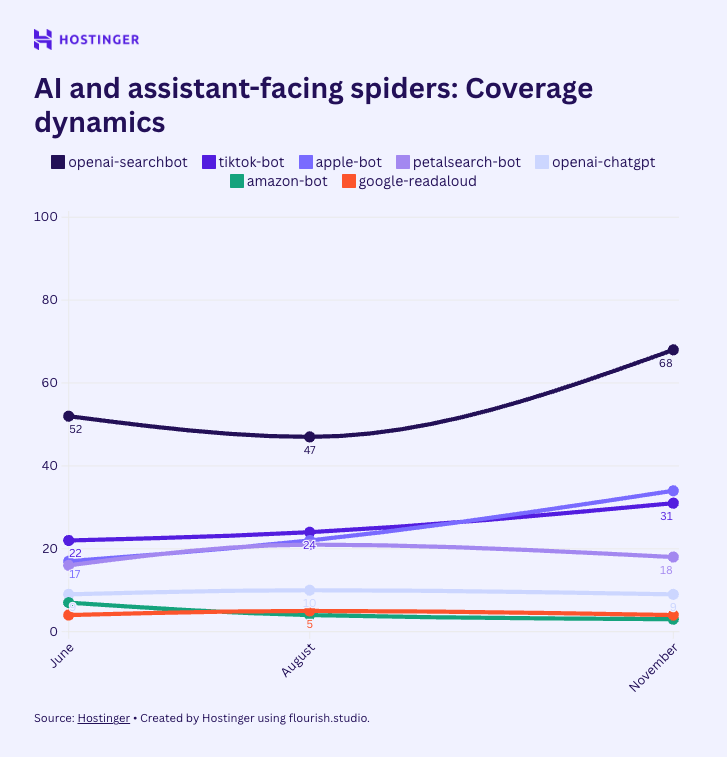
Ces robots n’aspirent pas le web en continu : ils interviennent à la demande, lorsqu’un utilisateur pose une question.
Résultat : ils sont perçus comme plus utiles… et mieux acceptés.
Une bascule silencieuse dans la découverte de contenus
La découverte de contenus ne passe plus uniquement par une page de résultats de moteur de recherche classique.
Progressivement, des réponses générées à partir de plusieurs sources remplacent la logique du lien unique.
Cela ne supprime pas les moteurs existants, mais introduit une concurrence directe sur l’attention.
Dans ce contexte, être visible ne signifie plus seulement « être bien positionné », mais aussi être sélectionné comme source.
Ce que les chiffres disent sur le blocage des robots
Un tableau permet de clarifier les différences de comportement observées.
| Type de robot | Objectif principal | Évolution de la couverture | Perception par les sites |
|---|---|---|---|
| Moteurs de recherche | Indexer pour le référencement | Stable | Indispensable |
| Collecte de données | Constitution de bases internes | En forte baisse | De plus en plus bloquée |
| Assistants conversationnels | Répondre à une requête utilisateur | En forte hausse | Plutôt acceptée |
Autrement dit, les sites ne rejettent pas les robots par principe. Ils arbitrent en fonction de la valeur perçue.
Les limites et zones d’incertitude à garder en tête
Tout n’est pas encore stabilisé. Plusieurs points restent flous. D’abord, la frontière entre exploration utile et collecte de données peut évoluer.
Un robot accepté aujourd’hui peut changer de comportement demain.
Ensuite, la mesure de la visibilité réelle apportée par ces nouveaux canaux reste difficile pour les sites web. Contrairement au référencement classique, les retombées sont moins mesurables, du fait de l’opacité des plateformes et de la forte personnalisation.
Enfin, l’équilibre économique n’est pas encore trouvé pour les éditeurs dont le modèle dépend fortement du trafic direct.
Cette étude ne décrit pas une rupture brutale, mais une transition.
La plupart des sites ne choisissent pas entre ouverture ou fermeture totale. Ils affinent. Ils observent. Ils testent.
La vraie question n’est donc pas « faut-il bloquer ou autoriser les robots », mais à qui, pour quoi, et dans quel objectif.

Rédactrice web pour LEPTIDIGITAL, je vous aide à décrypter l’actualité du numérique simplement. Pour me contacter : [email protected]