
Accès rapide (Sommaire) :
Un phénomène étrange dans les logs serveurs : les robots d’OpenAI changent-ils les règles du SEO ?
Depuis plusieurs mois, les professionnels du SEO observent un phénomène étrange dans leurs logs serveurs :
Les robots liés à OpenAI deviennent de plus en plus actifs.
Mais jusqu’ici, personne ne disposait d’un volume de données suffisamment massif pour comprendre ce qui se passait réellement.
C’est précisément ce qu’a tenté de faire Botify, en collaboration avec Chris Long, via l’analyse de plus de 7 milliards de logs issus d’un dataset global dépassant les 250 milliards d’événements.
Ils se sont donné pour objectif de comprendre comment les robots d’OpenAI explorent aujourd’hui le web.
Et les résultats vont clairement changer notre compréhension de la visibilité organique.
Avant : clics et indexation. Aujourd’hui : une nouvelle ère pour le SEO
Pendant des années, le référencement naturel reposait principalement sur une logique simple :
- Google crawlait les pages ;
- Google indexait les contenus ;
- les utilisateurs cliquaient depuis les résultats de recherche.
Avec les moteurs conversationnels, cette logique explose.
Désormais, un moteur peut :
- consulter une page sans générer de clic visible ;
- réutiliser des contenus stockés dans son propre index ;
- répondre directement à l’utilisateur sans qu’il visite le site source.
C’est exactement ce que suggère cette étude.
Et c’est probablement l’information la plus importante du rapport.
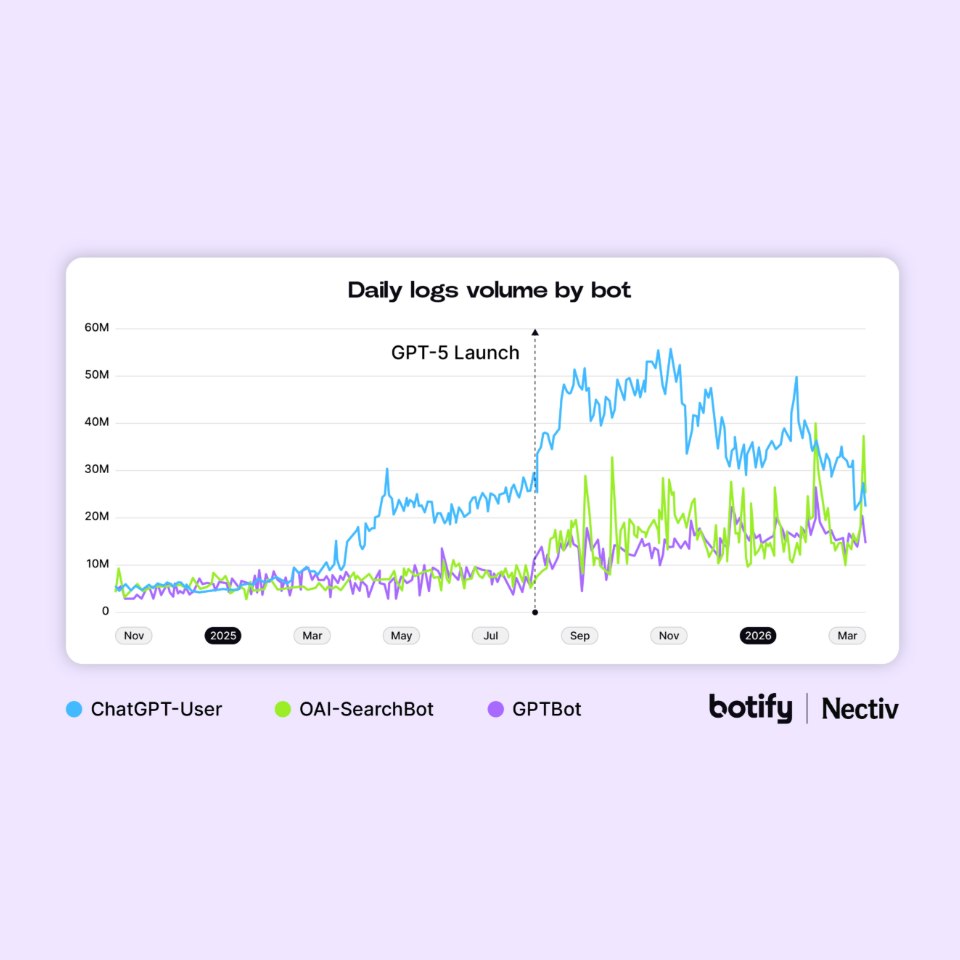
Trois robots OpenAI jouent désormais des rôles très différents
L’étude distingue clairement trois bots majeurs :
| Bot | Rôle principal | Fonction |
|---|---|---|
| ChatGPT-User | Navigation déclenchée après une requête utilisateur | Récupère les pages que le modèle souhaite lire |
| GPTBot | Entraînement des modèles | Collecte des contenus pour améliorer les connaissances du modèle |
| OAI-SearchBot | Moteur de recherche interne | Explore le web pour alimenter les réponses conversationnelles |
Cette distinction est fondamentale.
Beaucoup de professionnels mélangeaient encore ChatGPT-User et OAI-SearchBot.
Or ChatGPT-User ne correspondrait pas uniquement aux cas où un utilisateur demande explicitement “ouvre cette page”.
Le robot serait en réalité utilisé après les fameuses fan-out queries :
- le modèle lance des recherches web ;
- récupère des snippets et titres ;
- sélectionne certaines URLs ;
- puis déclenche ChatGPT-User pour récupérer le HTML complet.
Autrement dit : le modèle choisirait lui-même les contenus qu’il veut approfondir.
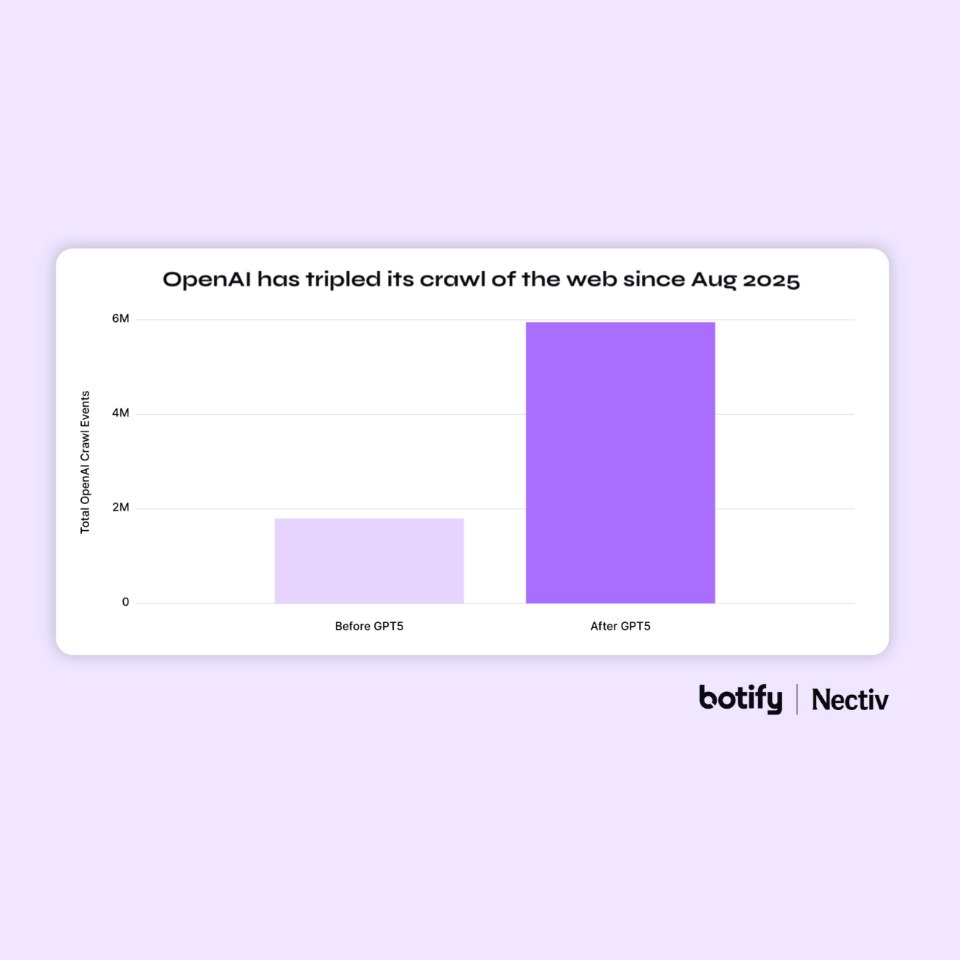
Le chiffre qui intrigue le plus : OpenAI a triplé son crawl depuis GPT-5
C’est probablement le point le plus spectaculaire du rapport.
Depuis le lancement de GPT-5 en août 2025 :
- OAI-SearchBot a augmenté son activité de 3,5x ;
- GPTBot a augmenté de 2,9x ;
- le crawl total d’OpenAI aurait été multiplié par 3.
Et cela change énormément de choses.
Pourquoi ?
Parce qu’OpenAI semble progressivement construire son propre index web autonome. Exactement comme Google.
OpenAI cherche probablement à réduire sa dépendance à Google
L’analyse apporte un éclairage particulièrement intéressant :
- scraper Google coûte extrêmement cher à grande échelle ;
- les risques juridiques augmentent ;
- OpenAI aurait donc intérêt à construire son propre index.
Cette hypothèse devient crédible quand on observe plusieurs signaux :
- les bots explorent massivement les sitemaps ;
- les recrawls deviennent fréquents ;
- les comportements ressemblent de plus en plus à ceux d’un moteur de recherche classique.
Le plus intéressant ?
Les courbes de GPTBot et OAI-SearchBot évoluent quasiment en parallèle.
Ce qui laisse penser que :
- l’entraînement des modèles ;
- et la construction d’un index de recherche ;
- avancent simultanément.
Pourquoi la baisse de ChatGPT-User pourrait être trompeuse ?
Le rapport révèle également un paradoxe étonnant :
ChatGPT-User aurait chuté de 28 % depuis décembre 2025.
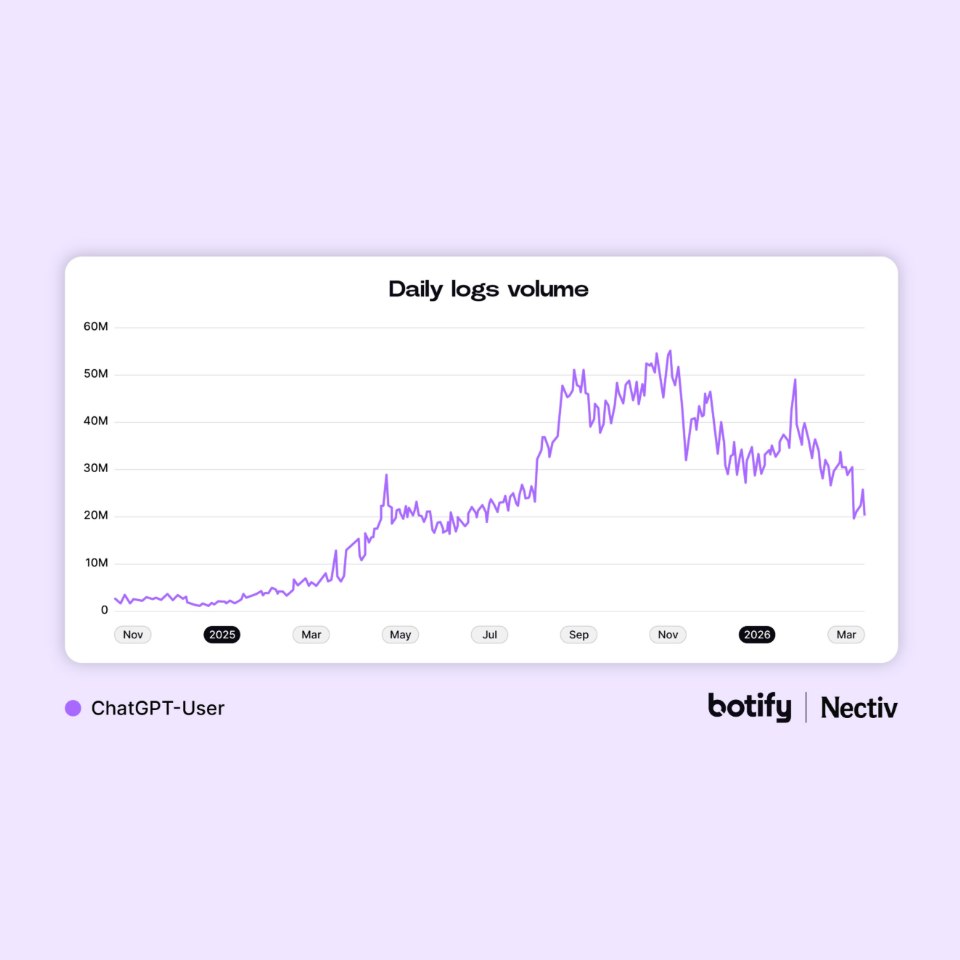
À première vue, cela pourrait laisser penser que l’usage de ChatGPT ralentit.
Mais l’explication pourrait être beaucoup plus technique.
Selon Botify, OpenAI pourrait désormais :
- utiliser davantage de contenus déjà stockés ;
- éviter certains fetchs temps réel ;
- s’appuyer sur un index HTML interne de plus en plus complet.
Autrement dit : moins de passages visibles ne signifie pas forcément moins d’utilisation.
Et c’est précisément ce qui inquiète déjà certains experts du GEO.
Les outils de mesure GEO pourraient devenir partiellement aveugles
C’est probablement l’une des réflexions les plus importantes du débat.
Si un moteur conversationnel peut :
- stocker une copie d’une page ;
- réutiliser cette connaissance sans revisiter le site ;
- citer une source sans nouveau crawl ;
alors une partie des outils actuels d’analyse deviendrait moins fiable.
En clair :
vous pourriez être utilisé dans les réponses… sans voir passer le robot dans vos logs.
C’est déjà partiellement ce que fait Gemini avec l’index de Google.
Et OpenAI semble avancer dans cette direction.
Tous les secteurs ne sont pas traités de la même manière par OpenAI
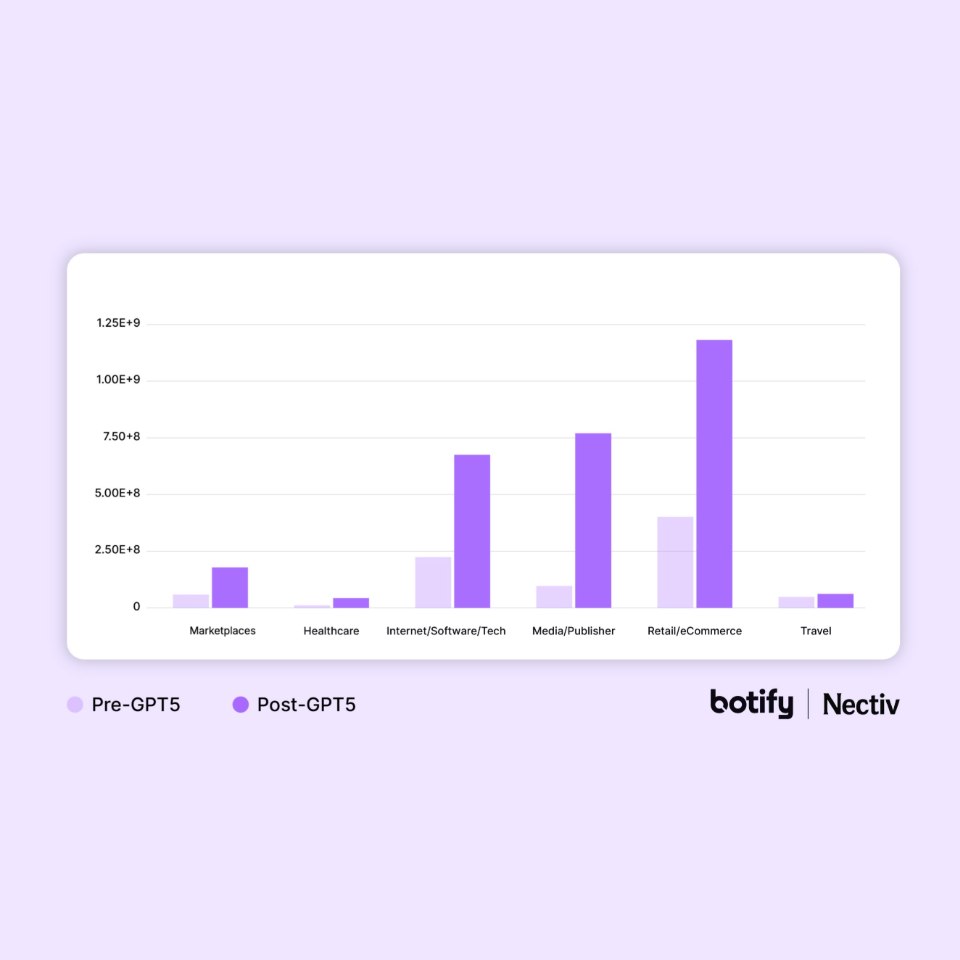
L’étude montre aussi des écarts très importants selon les industries.
| Secteur | Hausse d’OAI-SearchBot |
|---|---|
| Santé | +740,94 % |
| Médias / Publishers | +701,91 % |
| Marketplaces | +215,56 % |
| Tech / Software | +204,76 % |
| Retail / E-commerce | +194,96 % |
| Voyage | +29,81 % |
Pourquoi ces différences ?
Parce que certains secteurs nécessitent davantage de fraîcheur d’information.
Un média ou un site santé évolue constamment.
OpenAI doit donc explorer davantage ces contenus pour maintenir des réponses à jour.
À l’inverse, certains contenus e-commerce semblent davantage utilisés pour l’entraînement que pour la recherche temps réel.
Google reste largement dominant… mais l’écart se réduit vite
Le rapport évite un piège fréquent : croire qu’OpenAI rivalise déjà avec Google.
Nous en sommes encore loin.
Sur les 30 derniers jours analysés :
- Google représente environ 18,2 milliards d’événements ;
- OpenAI représente environ 887 millions.
Mais l’évolution est rapide.
En un an, OpenAI est passé de :
- 1,38 % du volume de crawl de Google ;
- à près de 4 %.
Et ce chiffre pourrait encore grimper rapidement si OpenAI déploie un index de recherche pleinement opérationnel.
Un nouveau modèle de référencement émerge : vers un web indexé en temps réel
Le sujet dépasse largement les simples logs techniques.
Ce qui se joue ici, c’est peut-être :
- la naissance d’un nouvel index web majeur ;
- une nouvelle forme de visibilité organique ;
- et potentiellement une nouvelle dépendance algorithmique.
Le plus frappant ?
Le modèle semble progressivement passer :
- d’une logique de “réponse basée sur la mémoire” ;
- à une logique “intelligente + web temps réel”.
Cela pourrait redonner énormément d’importance :
- à la structure technique des sites ;
- aux sitemaps ;
- à la fraîcheur éditoriale ;
- et aux signaux d’autorité.
Autrement dit : le SEO technique pourrait redevenir encore plus stratégique qu’il ne l’était déjà.
Le vrai sujet derrière cette étude : OpenAI prépare-t-il son propre Google ?
Impossible aujourd’hui d’affirmer avec certitude jusqu’où OpenAI ira.
Mais plusieurs signaux convergent :
- hausse massive du crawl ;
- construction probable d’un index ;
- augmentation des comportements de moteur de recherche ;
- importance croissante du web dans les réponses.
Le plus fascinant dans cette évolution, c’est peut-être que le référencement conversationnel pourrait bientôt dépendre autant :
- de ce que le modèle “connaît déjà” ;
- que de ce qu’il visite en direct.
C’est ce que certains commencent à appeler la visibilité paramétrique.
Et honnêtement, c’est probablement l’un des sujets les plus sous-estimés du moment.
Parce qu’à terme, il ne suffira peut-être plus seulement d’être bien positionné.
Il faudra aussi être suffisamment présent dans les corpus d’apprentissage… et dans les index internes des moteurs conversationnels.
Et vous, avez-vous déjà observé une hausse des bots OpenAI dans vos logs ?

Principalement passionné par les nouvelles technologies, l’IA, la cybersécurité, je suis un professionnel de nature discrète qui n’aime pas trop les réseaux sociaux (je n’ai pas de comptes publics). Rédacteur indépendant pour LEPTIDIGITAL, j’interviens en priorité sur des sujets d’actualité mais aussi sur des articles de fond. Pour me contacter : [email protected]


