
Accès rapide (Sommaire) :
Une plongée rare dans les coulisses de Google Discover
Metehan Yesilyurt, chercheur spécialisé en SEO et en visibilité sur les moteurs, a récemment publié une analyse technique détaillée du fonctionnement interne de Google Discover.
Son approche est particulière : il n’a pas étudié les recommandations officielles de Google mais a analysé le code de l’application Google elle-même, côté utilisateur.
Autrement dit : il a observé ce que l’application envoie, reçoit et enregistre pour comprendre comment le flux d’articles fonctionne.
Attention, cette analyse ne donne aucun accès aux algorithmes secrets de classement de Google Discover mais cela permet de voir :
- les étapes de traitement d’un article,
- les systèmes de filtrage en place,
- les mécanismes de personnalisation,
- les données internes suivies,
- et certaines priorités techniques.
Comment un article entre (ou non) dans Google Discover ?
L’analyse montre qu’un article suivrait une suite d’étapes bien définies avant d’apparaître dans le flux des utilisateurs.
Les grandes étapes du pipeline :
Voici le parcours simplifié :
- Crawl et indexation (Google découvre et enregistre la page)
- Extraction d’entités (identification des sujets et thèmes)
- Analyse des métadonnées (titre, auteur, image…)
- Classification en groupes (clusters)
- Filtrage éditeur et URL
- Correspondance avec les centres d’intérêt
- Classement final côté serveur
- Affichage dans le flux
- Analyse des réactions utilisateurs
Point clé : le filtrage au niveau du média intervient avant même le classement. Si un média est bloqué au niveau “collection”, ses articles ne seront même pas évalués pour apparaître dans le flux.
Schema.org passe avant Open Graph : un détail important
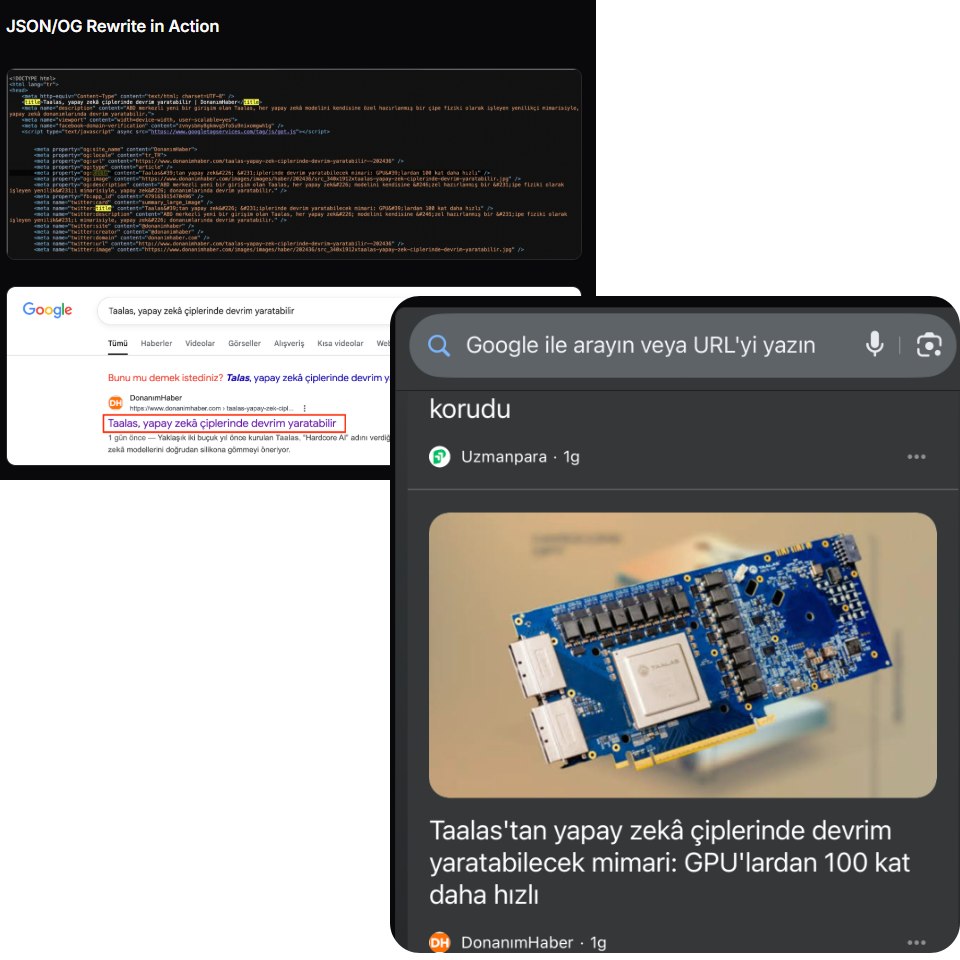
Beaucoup pensent que les balises Open Graph sont prioritaires mais selon l’analyse du code, ce sont d’abord les données structurées Schema.org qui sont lues par Google.
Pour le titre, l’auteur et l’éditeur, l’ordre est le suivant :
- Schema.org JSON-LD
- og:title
- twitter:title
- Balises génériques
En clair : si vos données structurées sont incorrectes ou mal optimisées, Discover peut afficher des informations erronées, même si vos balises Open Graph sont bonnes.
Pour les sites WordPress ou les équipes SEO, cela rend l’audit technique indispensable.
Le système de filtrage à deux niveaux : un risque sous-estimé
Le flux Discover applique deux types de filtres qui peuvent impacter la visibilité des articles ou d’un média :
| Niveau | Portée | Conséquence |
|---|---|---|
| Collection | Tout le média | Blocage global |
| Entity | Un article précis | Blocage individuel |
Si un utilisateur clique sur “Ne plus afficher ce média”, cela peut bloquer l’ensemble du site dans son flux.
Un article qui génère trop de réactions négatives peut donc pénaliser tous les autres.
Un enjeu majeur pour :
- les médias d’actualité,
- les sites à fort trafic,
- les marques dépendantes de Discover.
Le système NAIADES : le coeur de la personnalisation des recommandations d’articles Google Discover ?
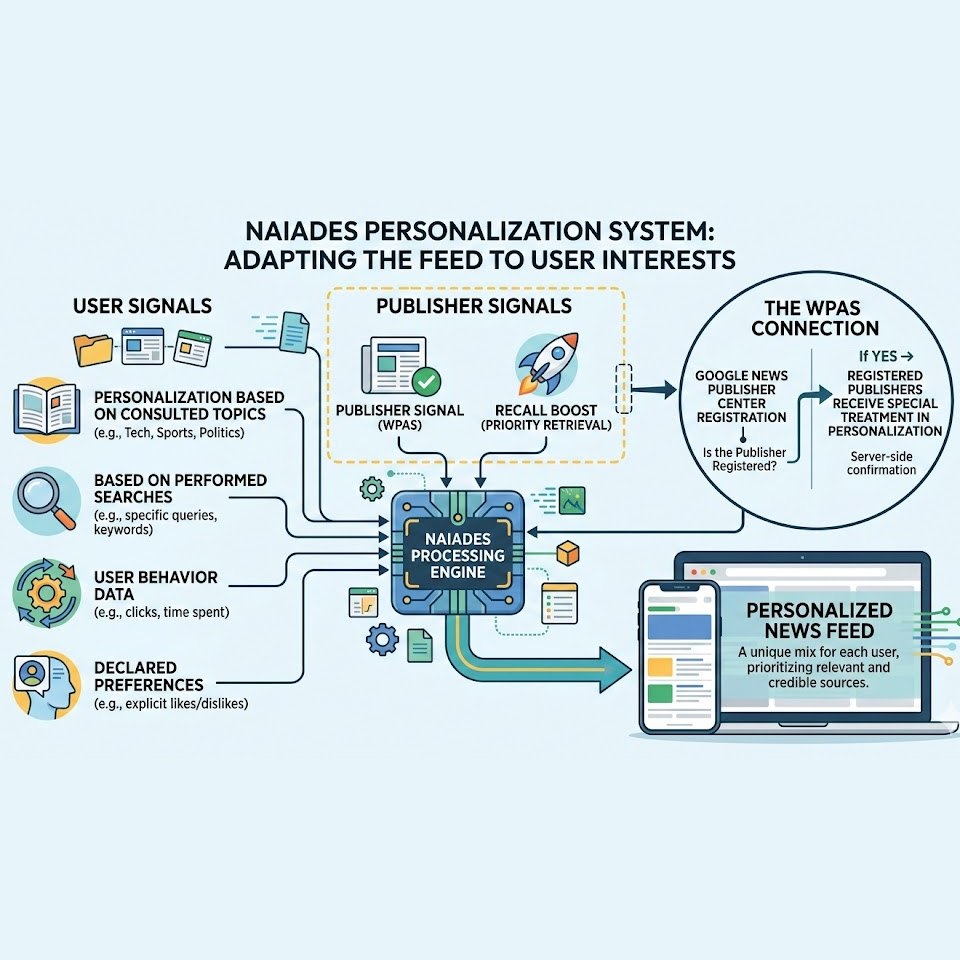
L’analyse mentionne un système interne appelé NAIADES qui servirait à adapter le flux aux intérêts de chaque utilisateur :
- Personnalisation basée sur les sujets consultés
- Basée sur les recherches effectuées
- Signal éditeur (WPAS)
- Priorité de récupération (recall boost)
Le signal WPAS semble lié à l’inscription au Google News Publisher Center mais ce n’est pas confirmé. Si cela se confirme côté serveur, les éditeurs enregistrés pourraient bénéficier d’un traitement particulier dans la personnalisation.
Un flux vivant et très évolutif : Discover fonctionne en continu
Discover n’est pas une simple page qui se recharge.
La connexion reste active en permanence.
- Des articles peuvent apparaître en temps réel.
- Un contenu peut être retiré après affichage.
- L’ordre peut changer pendant que vous scrollez.
Le flux est donc dynamique et évolue en continu.
Ce que cela signifie réellement pour votre stratégie
Ce qui est déjà exploitable :
- Soigner l’implémentation Schema.org.
- Utiliser une image principale d’au moins 1200px.
- Éviter les balises notranslate et nopagereadaloud.
- Réduire les signaux négatifs (titres trompeurs, putaclics, mauvaise expérience sur la page, popin intrusives).
Ce qui reste incertain :
- Le poids exact du signal WPAS.
- Les seuils précis de blocage.
- Les critères de classement internes.
Cette analyse concerne le fonctionnement visible de l’application. Les décisions finales restent contrôlées par Google côté serveur.

Fondateur de LEPTIDIGITAL et SUPASST, je suis également consultant spécialisé en acquisition de leads B2B (SaaS). Passionné par le marketing digital, l’intelligence artificielle et le SEO. Avant de devenir indépendant, j’ai occupé des postes clés en tant que SEO Manager et responsable e-commerce pour plusieurs grandes entreprises (Altice Media, Infopro Digital, Voyage Privé et le Groupe ERAM). Sur le plan perso, je suis un curieux insatiable, également passionné par la photographie, le badminton et les voyages. Pour toute demande de partenariat, privilégiez LinkedIn ou email ([email protected]).


