
Accès rapide (Sommaire) :
L’invasion silencieuse : quand les machines pillent le web sans rien laisser
Les données parlent d’elles-mêmes. Selon le rapport Akamai Digital Fraud & Abuse 2025, le trafic généré par les bots IA a progressé de 300 % en un an.
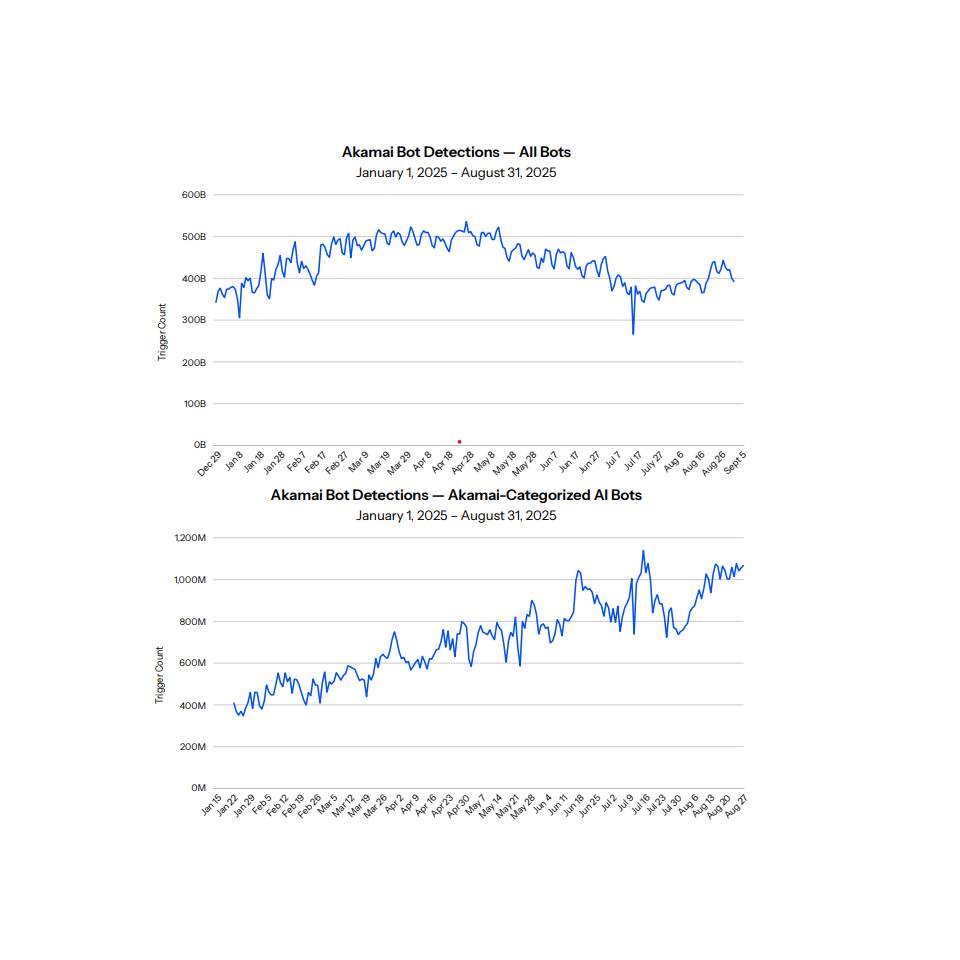
Sur le réseau TollBit, la proportion de visites attribuables à un agent automatisé est passée de 1 sur 200 en début d’année 2025 à 1 sur 31 aujourd’hui ,une multiplication par six en quelques mois à peine.
Les chiffres issus de l’infrastructure Kinsta sont encore plus parlants. Un seul bot a généré 3,75 millions de requêtes en 24 heures sur des URLs « add-to-cart », soit une requête toutes les 23 millisecondes en continu.
Sur trente jours, une unique règle de filtrage a suffi à bloquer 550 millions de requêtes issues de boucles d’exploration répétitives.
Derrière ces volumes, une réalité économique brutale : 80 % de ce trafic sert exclusivement à entraîner des modèles IA et ne génère aucun retour de visiteurs vers les sites sources.
Les éditeurs absorbent les coûts d’infrastructure. Les plateformes d’IA en captent la valeur.
Le vrai problème : ce n’est pas le volume, c’est le comportement
Pendant des années, les robots d’indexation se comportaient de manière prévisible : ils exploraient les pages, les référençaient, et repartaient.
Les nouveaux bots IA ont une logique radicalement différente.
Leur objectif n’est pas d’indexer pour renvoyer du trafic, mais d’aspirer un maximum de données pour alimenter des modèles de langage ou des systèmes de réponse conversationnelle.
Résultat : ces robots sont plus voraces, plus rapides, et fondamentalement moins disciplinés que tout ce qui existait avant — au point que certains ignorent même le fichier robots.txt.
Sur les sites WordPress et WooCommerce modernes, les pages produit génèrent des dizaines de variantes d’URL via les filtres de couleur, de taille, de tri ou de pagination.
Là où un humain voit une seule page, un bot en détecte des centaines d’URL distinctes et les explore toutes, en boucle, sans jamais reconnaître qu’il tourne en rond.
Selon Kinsta, ces boucles ont parfois tourné plusieurs jours sans être détectées avant qu’une règle d’infrastructure ne les intercepte.
Pourquoi votre serveur paie la facture à la place des IA ?
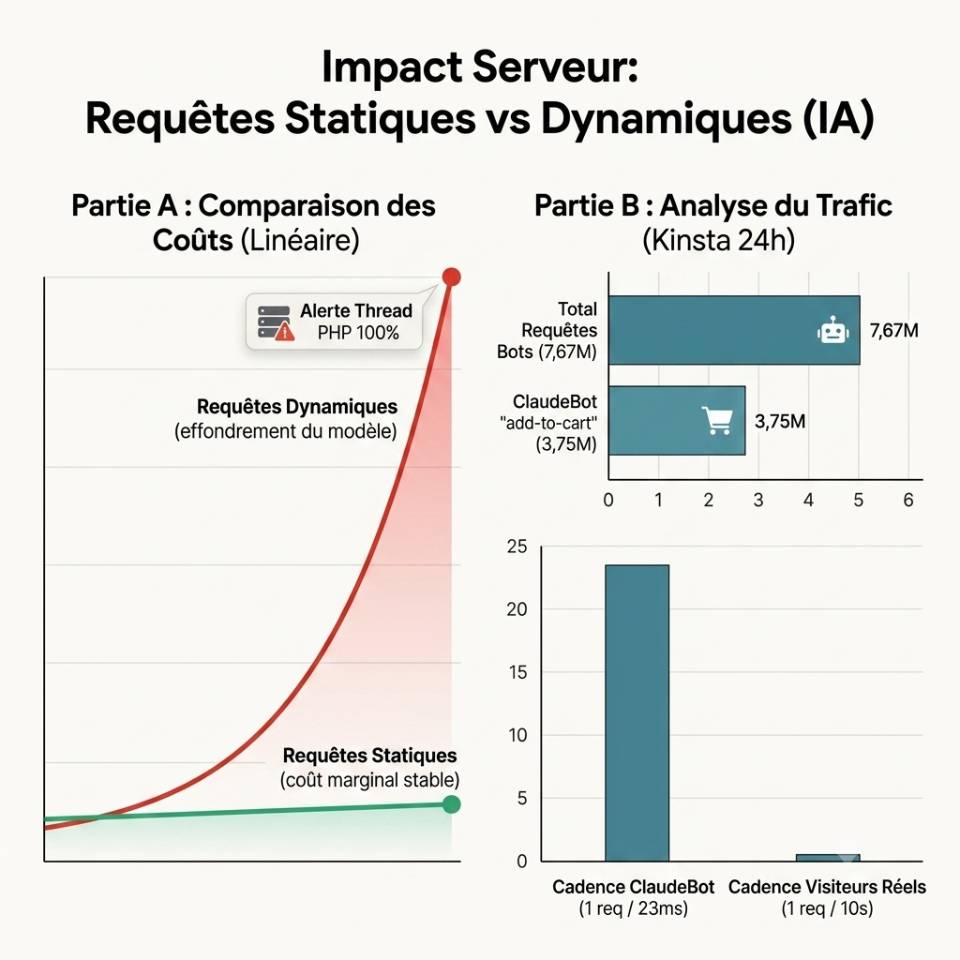
Sur une page statique mise en cache, chaque requête est bon marché : le serveur retourne une version déjà générée, le coût reste marginal.
Ce modèle s’effondre dès que les bots s’attaquent aux endpoints dynamiques, les plus courants sur les sites e-commerce :
- URLs
?add-to-cart=, pages panier et checkout - Pages produit avec filtres (couleur, taille, stock, tri)
- Requêtes de recherche interne
- Interactions AJAX et vues calendrier avec paramètres
Ces requêtes ne peuvent pas être servies depuis le cache.
Chacune d’elles déclenche l’exécution d’un thread PHP, des requêtes en base de données, et la gestion d’une session même quand le bot n’a aucune intention d’acheter quoi que ce soit.
7,67 millions de requêtes ont ciblé des URLs « add-to-cart » en seulement 24 heures sur un site observé par Kinsta. ClaudeBot en était à l’origine pour 3,75 millions d’entre elles soit une requête toutes les 23 millisecondes, nuit et jour.
À cette cadence, les threads PHP s’épuisent, les vrais visiteurs attendent, et les coûts d’hébergement s’envolent.
Les éditeurs financent l’infrastructure que les IA consomment, sans retour de trafic en contrepartie dans 80 % des cas.
Conséquences par domaine : enjeux et impacts opérationnels
| Domaine impacté | Problème observé | Risque concret |
|---|---|---|
| Infrastructure / Hébergement | Surcharge des endpoints dynamiques | Hausse des coûts serveur, ralentissements, saturation des threads PHP |
| Analytics | Trafic bot gonflant les métriques | Données d’audience faussées, décisions marketing biaisées |
| SEO technique | Crawl budget gaspillé sur des URLs sans valeur | Indexation ralentie des pages stratégiques |
| E-commerce (WooCommerce) | Boucles infinies sur pages panier / filtres | Dégradation des performances pour les vrais acheteurs |
| Contenu / Médias | Aspiration des données sans retour de trafic | Perte de valeur économique sur le contenu produit |
Bloquer ou laisser passer : la mauvaise question
Face à ces constats, la réaction instinctive est souvent de tout bloquer. C’est une erreur.
Googlebot représente à lui seul environ 4,5 % des requêtes HTML sur le réseau Cloudflare, davantage que l’ensemble des bots IA non-Google réunis. Le bloquer pour alléger la charge serveur serait contre-productif.
La bonne question n’est pas « bloquer ou autoriser les bots ? » mais « quels bots, sur quelles parties du site, dans quelles conditions ? » C’est une logique de politique par chemin, pas de règle universelle.
Kinsta recommande une approche graduée selon le type de site :
- Googlebot / Bingbot : autoriser, mais bloquer l’accès aux URLs
/cart,/checkoutet?add-to-cart=via robots.txt. - Bots IA d’entraînement (GPTBot, ClaudeBot, Amazonbot) : soumettre à challenge au niveau WAF, ils n’ont aucun intérêt légitime à accéder aux pages panier.
- Bots non vérifiés : bloquer sur les endpoints sensibles, aucune raison valable d’y accéder.
- Vos propres automatisations (outils de sync, monitoring) : whitelister explicitement par plage IP.
Les métriques qui comptent encore dans un web saturé de bots
Lorsque le trafic automatisé gonfle artificiellement les compteurs de visites, les volumes bruts ne reflètent plus la réalité. Kinsta identifie les indicateurs qui conservent leur pertinence :
- Volume de recherches de marque (branded search).
- Trafic direct.
- Qualité de l’engagement (temps passé, profondeur de session).
- Conversions et revenus liés à un comportement humain réel.
Si ces métriques progressent, vous êtes visible là où ça compte. Si seuls les volumes de sessions augmentent, vous financez l’entraînement des IA sans contrepartie.
Kinsta anticipe également l’émergence du trafic agentique ; des agents IA conçus non plus pour scraper du contenu, mais pour déclencher des actions sur les sites.
Google a d’ores et déjà annoncé un user-agent dédié pour identifier ces interactions.
Les plateformes responsables s’identifieront et respecteront les délais de crawl. Les autres, non. La frontière entre visiteur humain et agent automatisé va continuer de s’effacer.
Alors, votre site sait-il aujourd’hui distinguer un vrai visiteur d’un bot qui lui coûte de l’argent sans lui rapporter quoi que ce soit ?

Principalement passionné par les nouvelles technologies, l’IA, la cybersécurité, je suis un professionnel de nature discrète qui n’aime pas trop les réseaux sociaux (je n’ai pas de comptes publics). Rédacteur indépendant pour LEPTIDIGITAL, j’interviens en priorité sur des sujets d’actualité mais aussi sur des articles de fond. Pour me contacter : [email protected]


