Comment simplement extraire du texte d’une image scannée au format PDF à l’aide d’un outil de reconnaissance optique de caractères ?
Comment Extraire le Texte d’une Image PDF en 4 Étapes ?
Vous souhaiteriez récupérer uniquement le texte présent sur une image, mais elle est au format PDF et vous ne savez pas comment faire ? Et si nous vous disions que vous pouviez le faire simplement à l’aide d’un outil de reconnaissance optique de caractères ? Nous allons vous présenter la démarche à suivre en quelques étapes (seulement 4 !) à l’aide d’un outil dédié.

Extraire le texte d’un document ou d’une image scannée en PDF est très simple avec des outils comme Wondershare PDFelement, voici comment procéder en 4 étapes simples.
Envie de tester WondersharePDF Elements ?
Service is unavailable or invalid API key.
Wondershare PDF Elements
Outil puissant et professionnel
Accès rapide (Sommaire) :
1. Téléchargez et installez le logiciel Wondershare PDFelement
Wondershare PDFelement est un outil très utile pour l’extraction de texte d’une image au format PDF. En vous rendant sur le site officiel, il vous sera possible de le télécharger (version Windows ou Mac) et de l’utiliser gratuitement pendant 20 jours, durée de la période d’essai.
La version d’essai gratuite de l’outil est toutefois un peu bridée. Un filigrane sera par exemple ajouté à tous les fichiers exportés et la fonctionnalité OCR (indispensable ici) ne sera pas disponible. Si vous souhaitez bénéficier de toute la puissance de l’outil pour des besoins réguliers et plus professionnels, une licence n’est pas très onéreuse comparée aux services que peut rendre l’outil, libre à vous donc de vous le procurer ou non.
Une fois la version d’essai ou la version finale téléchargée sur votre PC ou Mac, lancez l’installation. L’installation complète, vous devriez voir cet écran s’afficher devant vous :
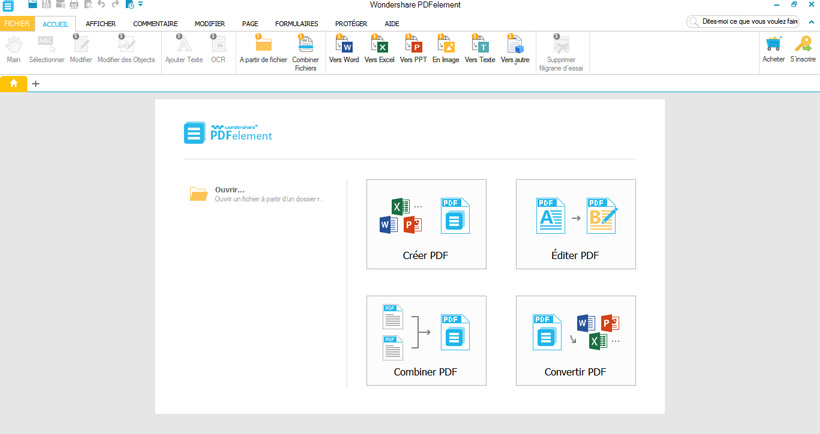
Cet écran d’accueil vous présente les différentes possibilités de l’outil hors extraction de texte des images. Wondershare PDFelement vous permet notamment :
- De combiner plusieurs PDF entre eux,
- D’éditer n’importe quel PDF non crypté,
- De crypter des fichiers PDF,
- De convertir des PDF en fichiers Word, Powerpoint, Excel…
2. Ouvrez l’image PDF dont vous souhaitez extraire le texte
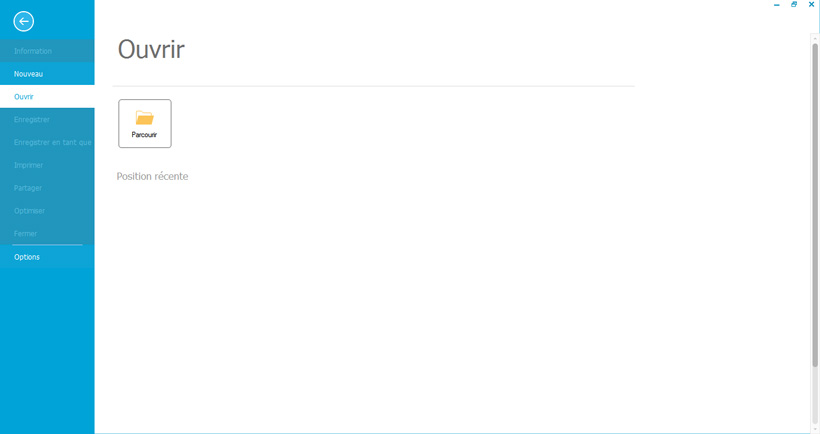
La seconde étape est on ne peut plus simple : il vous suffit d’ouvrir l’image PDF qui contient le texte que vous souhaitez extraire directement depuis l’outil.
Pour ce faire, cliquez sur « Ouvrir un fichier à partir d’un fichier récent » ou cliquez sur « Fichier » => « Parcourir ».
Il vous est possible d’importer un ou plusieurs fichiers PDF.
3. Utilisez la fonctionnalité OCR de Wondershare PDFelement pour détecter et extraire le texte de l’image
Une fois vos fichiers PDF importés dans le logiciel, il vous faudra utiliser la fonctionnalité OCR pour extraire le texte des images PDF ouvertes.
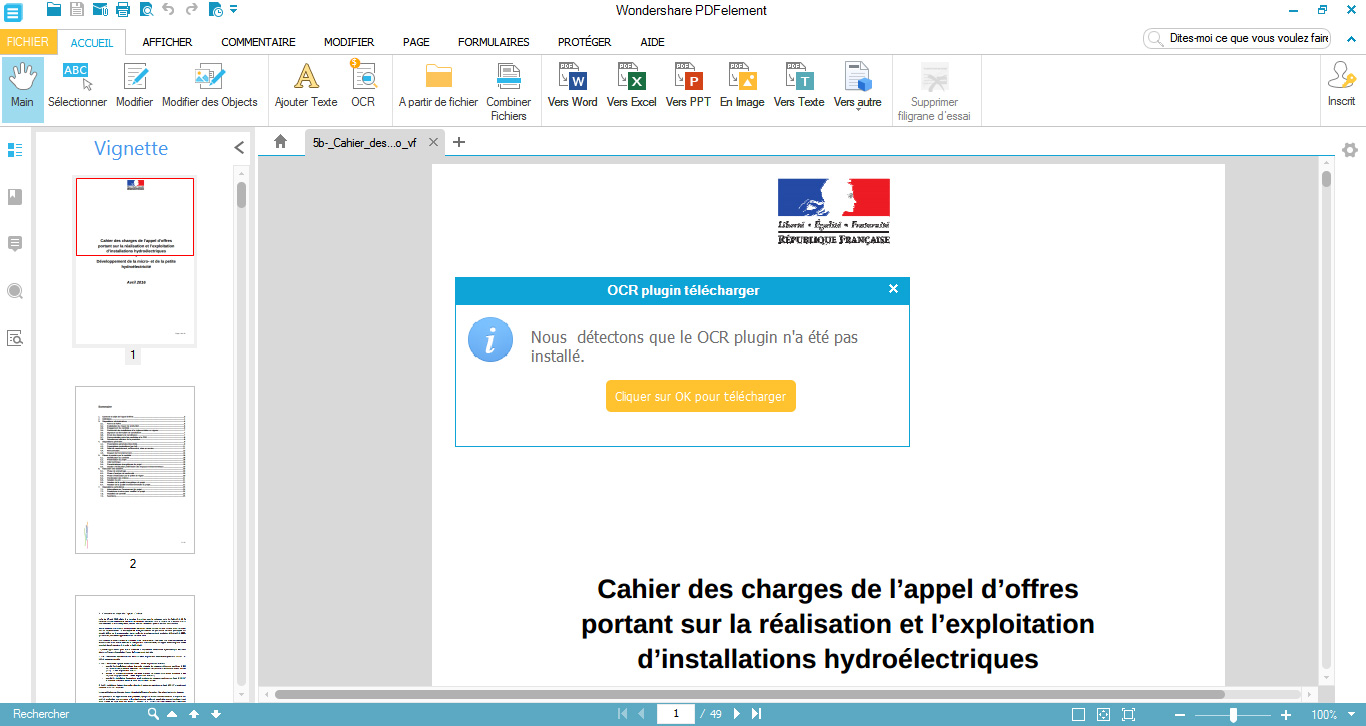
De manière automatisée, PDFelement détectera que vous avez importé un élément scanné. Il vous proposera ainsi automatiquement d’activer le plug-in OCR indispensable à l’extraction du texte de l’image scannée (cette possibilité n’est pas offerte aux utilisateurs qui ne disposent que de la version d’essai).
Cliquez sur « Exécuter OCR » sur le bandeau qui s’affichera, puis sélectionnez la langue du document importé. Cliquez ensuite sur « OK ».
Bon à savoir : Si vous ne changez pas la langue par défaut, le logiciel tentera de détecter le texte en anglais uniquement.
4. Utilisez la fonctionnalité OCR de Wondershare PDFelement pour détecter et extraire le texte de l’image (PDF)

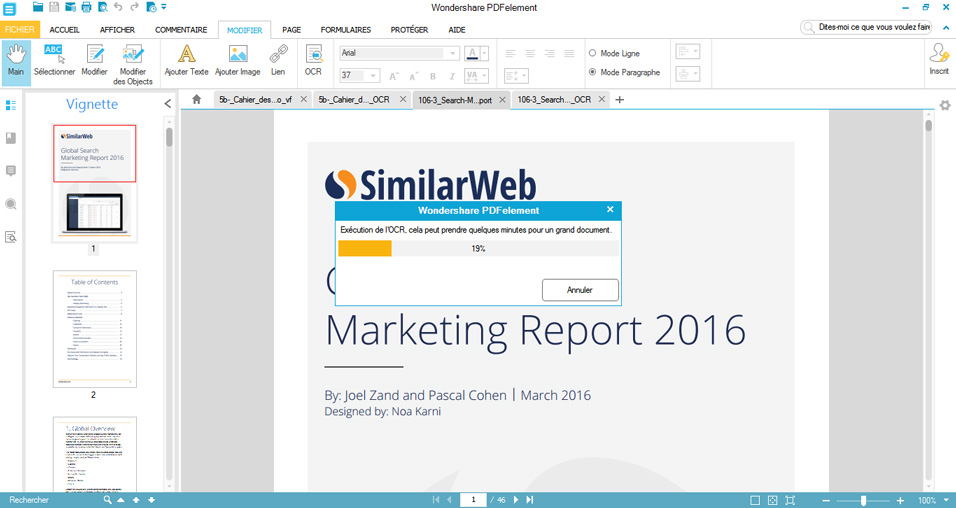
Après avoir lancé l’exécution du plug-in OCR, vous devrez patienter quelques secondes / minutes, puis il vous sera possible de modifier le texte extrait du PDF scanné.
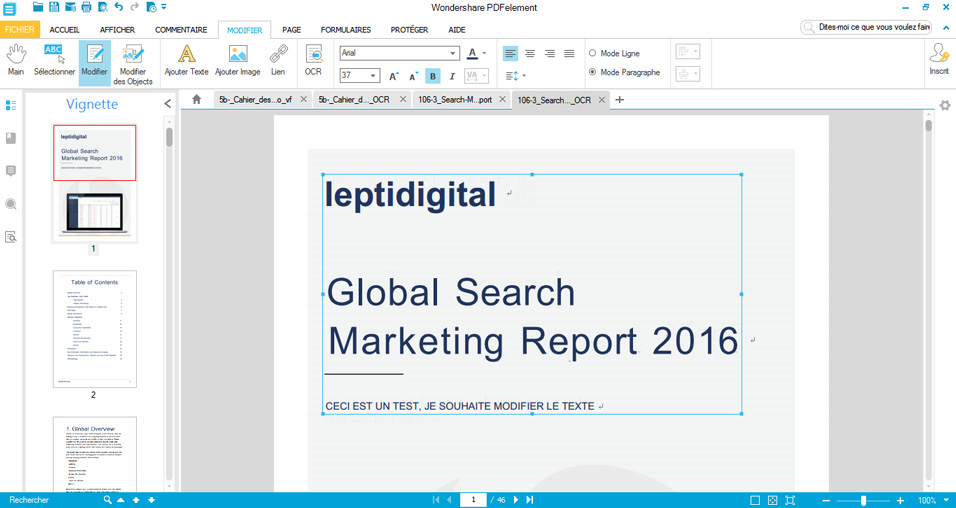
Pour extraire l’intégralité du texte d’un document numérisé au format PDF, il vous suffira de suivre cette procédure :
- Rendez-vous dans l’onglet « Modifier »
- Cliquez sur l’icône « Modifier »
- Sélectionnez sur le PDF les textes à éditer puis modifiez-les à votre convenance avant d’enregistrer
Si jamais vous souhaitez convertir l’intégralité du fichier PDF au format Word, c’est aussi parfaitement faisable depuis le logiciel en cliquant simplement sur « En Word » depuis l’onglet « Accueil » du logiciel.
Pour aller plus loin, nous vous présentions il y a peu une liste de logiciels OCR capables de transformer n’importe quel fichier PDF scanné en document Word éditable, n’hésitez pas à vous y référer pour découvrir toutes les solutions disponibles.
MAJ : Depuis la rédaction de cet article sur l’extraction de texte d’une image PDF, l’interface du logiciel présenté dans l’article (Wondershare PDFelement) a depuis évoluée et de nouvelles fonctionnalités ont été ajoutées par l’outil.
Envie de tester WondersharePDF Elements ?
Service is unavailable or invalid API key.
Wondershare PDF Elements
Outil puissant et professionnel
FAQ sur l’extraction de texte d’un PDF
Pourquoi chercher à extraire du texte d’un document PDF ?
Selon les situations, il peut y avoir un grand nombre de raisons pour lesquelles on peut chercher à extraire du texte d’un document PDF. En voici quelques-unes :
- Faciliter la recherche : en extrayant le texte d’un document PDF, il devient possible de le rechercher et de le filtrer à l’aide d’outils de recherche de texte. Cela peut être particulièrement utile pour les documents volumineux.
- Améliorer l’accessibilité : en extrayant le texte d’un document PDF, il devient possible de le rendre accessible aux personnes atteintes de handicaps visuels ou auditifs. Le texte peut être converti en braille, lu à haute voix par un logiciel de synthèse vocale ou présenté sous forme de sous-titres.
- Faciliter la réutilisation : en extrayant le texte d’un document PDF, il devient possible de le copier et de le coller dans d’autres documents ou applications. Cela peut être particulièrement utile si vous avez besoin de citer ou de réutiliser des informations contenues dans le PDF.
- Accélérer le traitement : en extrayant le texte d’un document PDF, il devient possible de l’analyser automatiquement à l’aide d’algorithmes de traitement de texte. Cela peut être une fonctionnalité intéressante si vous devez extraire des données spécifiques, telles que des noms ou des adresses, à partir du PDF.
Comment fonctionnent les logiciels d’extraction de texte ?
Les logiciels d’extraction de texte utilisent des algorithmes de reconnaissance optique de caractères (OCR) pour analyser les images de texte contenues dans un document PDF et les convertir en texte éditable. Voici les étapes générales du processus :
- Le logiciel d’extraction de texte analyse chaque page du document PDF et identifie les zones contenant du texte.
- Le logiciel d’extraction de texte utilise l’OCR pour reconnaître les caractères dans chaque zone de texte et les convertir en texte éditable.
- Le logiciel d’extraction de texte combine le texte extrait de toutes les zones de texte pour créer une version éditable du document PDF.
Quels sont les avantages et les inconvénients de l’extraction de texte ?
Les avantages de l’extraction de texte à partir de documents PDF sont nombreux. Ils permettent de :
- Gagner du temps : en évitant la saisie manuelle de chaque mot contenu dans le PDF.
- Améliorer la précision : en utilisant des algorithmes de reconnaissance de caractères pour identifier et convertir automatiquement les caractères dans les images de texte.
- Accéder à des informations cachées : en identifiant des informations cachées dans le document PDF, comme des métadonnées qui ne sont pas visibles à l’œil nu.
Cependant, il y a aussi des limites à l’extraction de texte à partir de documents PDF. Les limites peuvent inclure :
- Précision limitée : les logiciels d’extraction de texte peuvent ne pas être en mesure de reconnaître certains caractères ou d’interpréter correctement certaines polices ou mises en page.
- Nécessité de correction manuelle : même les meilleurs logiciels d’extraction de texte peuvent produire des erreurs, et il peut être nécessaire de relire et de corriger manuellement le texte extrait.
- Complexité des documents : les documents PDF qui contiennent des graphiques, des tableaux ou d’autres éléments non textuels peuvent être plus difficiles à extraire que les documents textuels simples.
La qualité du texte est-elle dégradée lorsqu’il est extrait d’un document PDF ?
La qualité du texte extrait d’un document PDF dépend de plusieurs facteurs. Dans certains cas, la qualité du texte peut être légèrement dégradée lorsqu’il est extrait d’un document PDF, mais dans d’autres cas, il peut être très proche de la qualité de l’original.
Lorsqu’un document PDF est créé, il peut être créé à partir de plusieurs sources, y compris des fichiers texte, des fichiers image et des fichiers de traitement de texte. Si le document PDF est créé à partir d’un fichier texte, le texte sera généralement de haute qualité et sera facilement extrait avec précision.
Cependant, si le document PDF est créé à partir d’un fichier image, la qualité du texte extrait dépendra de la qualité de l’image de texte d’origine. Si l’image de texte est floue, pixélisée ou de faible résolution, cela peut affecter la qualité du texte extrait.
La qualité de la reconnaissance optique de caractères utilisée par le logiciel d’extraction de texte peut aussi avoir un impact sur la qualité du texte extrait. Les algorithmes OCR modernes sont généralement très précis et peuvent extraire du texte avec une grande précision. Et certains types de police, comme les polices manuscrites, peuvent être plus difficiles à extraire avec précision.
Quels sont les développements futurs possibles en matière d’extraction de texte à partir d’images ou de PDF ?
Les développements futurs possibles en matière d’extraction de texte à partir d’images ou de PDF sont infinis !
Cela pourrait tout d’abord inclure l’amélioration de la précision de l’OCR. Les algorithmes OCR sont de plus en plus précis grâce aux avancées en matière d’intelligence artificielle et de traitement du langage naturel et de nouveaux progrès dans ce domaine pourraient rendre l’extraction de texte encore plus fiable et plus précise qu’elle ne l’est déjà.
L’automatisation de la correction de texte pourrait aussi être mise en place. Comment ? Les logiciels d’extraction de texte pourraient utiliser des algorithmes d’apprentissage automatique pour corriger les erreurs et améliorer la qualité du texte extrait sans intervention humaine.
La prise en charge de documents multilingues ne devrait pas tarder à voir le jour. Les logiciels d’extraction de texte pourraient être améliorés pour prendre en charge plusieurs langues, permettant ainsi l’extraction de texte à partir de documents multilingues.
Si l’on va plus loin, d’autres développements pourraient être possibles :
- L’extraction de texte en temps réel : Les logiciels d’extraction de texte pourraient être intégrés dans les appareils mobiles et les caméras pour permettre l’extraction de texte en temps réel, par exemple en pointant simplement l’appareil vers un document.
- L’extraction de données structurées : Les logiciels d’extraction de texte pourraient être améliorés pour extraire des données structurées à partir de documents PDF, telles que des tableaux et des graphiques, ce qui pourrait faciliter leur utilisation dans des applications de traitement de données.
- L’intégration de l’analyse sémantique : Les logiciels d’extraction de texte pourraient être améliorés pour comprendre le sens des mots et des phrases extraits, permettant ainsi une analyse sémantique plus poussée du contenu des documents PDF.
Cet article a été rédigé par LEPTIDIGITAL dans le cadre d’un partenariat payant avec Wondershare PDFelement
Avant de se quitter…
Si cet article sur les étapes pour extraire le texte d’une image au format PDF vous a plu, n’hésitez pas à le partager sur les réseaux sociaux et à vous abonner à notre newsletter digitale pour recevoir nos prochains articles.
Vous pouvez également suivre nos meilleurs articles via notre flux RSS : https://www.leptidigital.fr/tag/newsletter-digitale/feed/ (il vous suffit de l’insérer dans votre lecteur de flux RSS préféré (ex : Feedly)).
Nous sommes aussi actifs sur Linkedin, Twitter, Facebook et YouTube. On s’y retrouve ?
Pour toute question associée à cet article, n’hésitez pas à utiliser la section « commentaires » pour nous faire part de votre remarque, nous vous répondrons dans les meilleurs délais (avec plaisir).

Fondateur de LEPTIDIGITAL et SUPASST, je suis également consultant spécialisé en acquisition de leads B2B (SaaS). Passionné par le marketing digital, l’intelligence artificielle et le SEO. Avant de devenir indépendant, j’ai occupé des postes clés en tant que SEO Manager et responsable e-commerce pour plusieurs grandes entreprises (Altice Media, Infopro Digital, Voyage Privé et le Groupe ERAM). Sur le plan perso, je suis un curieux insatiable, également passionné par la photographie, le badminton et les voyages. Pour toute demande de partenariat, privilégiez LinkedIn ou email ([email protected]).
Ceci pourrait vous intéresser :


C’est récent




![]()
Lancé en 2014 et aujourd’hui visité chaque mois par plusieurs centaines de milliers de professionnels du numérique, LEPTIDIGITAL est un média marketing digital vous proposant le meilleur de l’actualité digitale (Intelligence Artificielle, SEO, Webmarketing, Social Media, SEA, Emailing, E-commerce, Growth Hacking, UX, Hébergement web, WordPress…) en plus d’astuces et tutoriels détaillés.
Vous souhaitez…