L’outil de Gestion des Paramètres d’URLs de la Search Console sera Bientôt Supprimé ! Quelles Alternatives ?
L’outil de gestion des paramètres d’URLs de la Search Console va être supprimé et non remplacé. Quelles alternatives utiliser pour gérer et optimiser son crawl budget ?
L’outil de gestion des paramètres d’URL, lancé en 2009, sera supprimé le 26 Avril 2022 de la Search Console. Il ne sera pas remplacé par un autre outil. Explications et alternative.
Pourquoi supprimer l’outil de gestion des paramètres d’URLs de la Search Console ?
Selon Google, l’outil de gestion des paramètres d’URLs n’est plus d’actualité puisque son robot d’exploration est désormais en mesure d’automatiquement détecter les paramètres inutiles.
Selon le moteur de recherche, seuls 1% des paramétrages en place sur l’intégralité des sites seraient encore utiles pour gérer le crawl des URLs avec des paramètres.
Quel était l’intérêt de cet outil ?
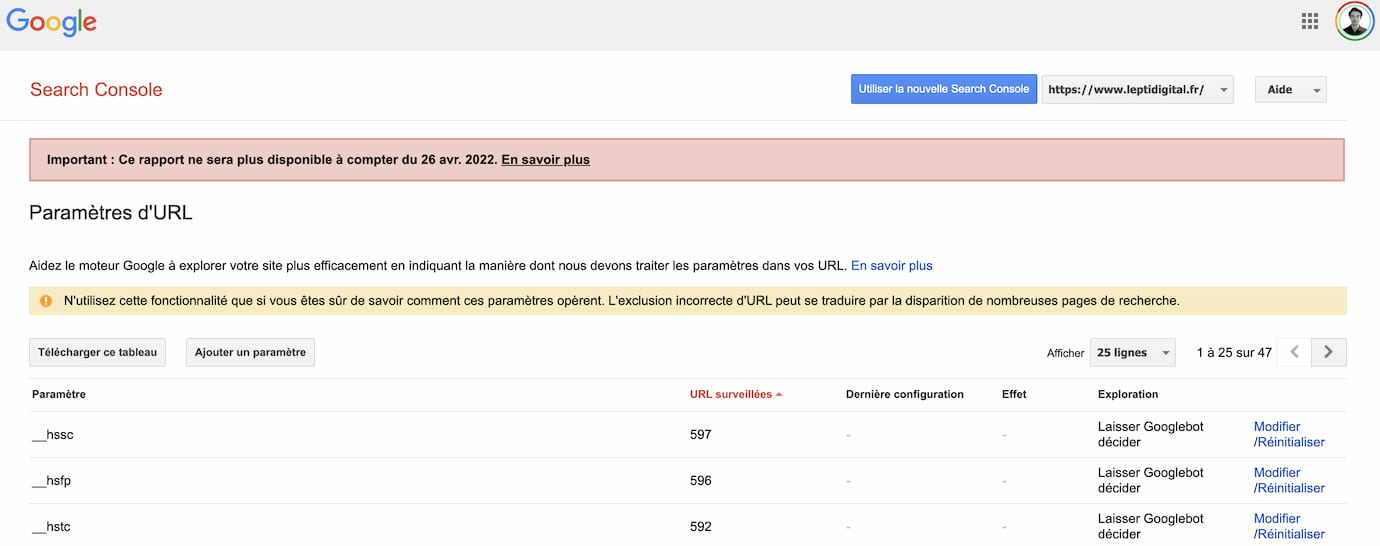
Aperçu de l’outil de gestion des paramètres d’url dans Google Search Console
Forcer Google à ne pas parcourir des paramètres d’URLs qui entrainaient la création d’URLs en double
Forcer Google à ne parcourir que certains paramètres d’URLs
Empêcher Google de parcourir les pages avec des ID de sessions
Quelles alternatives à l’outil de gestion des paramètres d’URLs pour gérer le crawl de Google ?
1- Le robotos.txt
Bien que Google indique que les webmasters n’auront rien à faire suite à la suppression effective de l’outil prévue en Avril 2022, rien n’empêche les référenceurs et webmasters de sécuriser leurs arrières en optimisant leur fichier robots.txt avec des directives « allow » pour autoriser sélectivement le crawl et « disallow » pour le bloquer.
Le fichier robots.txt, que l’on retrouve à la racine des sites web (qui en disposent), est le fichier indispensable à optimiser lorsque l’on souhaite optimiser le crawl de Googlebot (et des autres robots d’exploration des moteurs de recherche) et son crawl budget.
Des directives « Disallow: » pourront ainsi toujours être placées dans le robots.txt pour forcer Google à ne pas parcourir les pages contenant des paramètres d’URLs spécifiques.
Voici un exemple de règle simple que l’on peut placer dans le robots.txt pour décider d’interdire le crawl de googlebot à toutes les urls qui contiendraient par exemple le paramètre « filtre= » :
Disallow: /*filtre=*
Les étoiles signifient ici que peu importe ce qui se trouve avant ou après « filtre= » dans l’URL, à partir du moment ou l’url contient ce paramètre, elle ne doit pas être suivie.
A l’inverse, il sera également possible de se servir de la directive « allow » pour indiquer à Google que l’on souhaite qu’il continue de crawler certains paramètres qu’il aurait pu décider de lui même de ne plus crawler suite à la suppression de l’outil de gestion des paramètres d’URLs.
2- Les balises hreflang pour les URLs avec des paramètres associées aux variantes linguistiques
Si tu utilises les paramètres d’URLs pour distinguer les pages traduites dans différentes langues, tu pourras si ce n’est pas déjà le cas mettre en place les balises <link rel= »alternate » hreflang= » » > pour t’assurer que Google continue bien de crawler les différentes variantes.
Comment contrôler que googlebot crawle bien les bonnes URLs ?
Pour t’assurer que tes nouvelles directives (ou anciennes) fonctionnent comme tu le souhaites après la suppression de l’outil de gestion des paramètres d’URLs, tu peux dans un premier temps tester chaque URL de ton choix dans l’outil de test du fichier robots.txt intégrer dans la Search Console.
Ensuite, pour une vérification plus poussée et plus macro, l’idéal est d’avoir recours à un logiciel d’analyse de logs SEO qui te permettra de voir clairement où Google passe et où il ne passe pas / plus afin d’ajuster tes directives en conséquence.
Fondateur de LEPTIDIGITAL et SUPASST, je suis également consultant spécialisé en acquisition de leads B2B (SaaS). Passionné par le marketing digital, l’intelligence artificielle et le SEO. Avant de devenir indépendant, j’ai occupé des postes clés en tant que SEO Manager et responsable e-commerce pour plusieurs grandes entreprises (Altice Media, Infopro Digital, Voyage Privé et le Groupe ERAM). Sur le plan perso, je suis un curieux insatiable, également passionné par la photographie, le badminton et les voyages. Pour toute demande de partenariat, privilégiez LinkedIn ou email ([email protected]).